
Методы обработки данных наблюдений — Энциклопедия по экономике
Методы обработки данных наблюдений [c.109]Изучение затрат рабочего времени независимо от метода и вида наблюдений организуется по следующим этапам подготовка к наблюдению проведение наблюдений обработка данных наблюдений анализ результатов обработки разработка норм труда и предложений по совершенствованию организации труда. [c.60]
Метод моментных наблюдений относится к методам групповой несплошной фотографии рабочего времени, осуществляемой специальным наблюдателем. При этом методе наблюдатель через установленные интервалы записывает, чем заняты рабочие в данный момент. Преимуществом этого метода являются его простота и возможность в короткий срок при работе одного наблюдателя получить данные о затратах рабочего времени большого числа одновременно работающих исполнителей. Моментные наблюдения проводят, как и фотографию рабочего времени, в три этапа подготовительный, процесс наблюдения и обработка данных наблюдения.

Оперативный анализ, проводимый по ходу производства, возможен на всех уровнях управления. Особенность оформления его результатов связана прежде всего с механизацией или автоматизацией учета и контроля и внедрением оперативных методов обработки данных. В первичных звеньях оперативный анализ проводится углубленно, по всем объектам и по кругу показателен, которые претерпевают постоянные изменения. В вышестоящих органах оперативный анализ, как правило, не носит сквозного характера. Он базируется на выборочных наблюдениях и имеет характер экспресс-анализа, т. е. быстрой проработки выборочных данных с целью улавливания тенденций нх изменения. Выводы оперативного анализа чаще всего оформляются в виде конкретных сигналов, направленных непосредственным исполнителям для корректировки их деятельности. [c.128]
Лабораторный метод основан на наблюдениях, производимых в специально созданных условиях в лабораториях. Порядок замеров, обработки данных наблюдений и проектирование норм те же, что и при производственном методе нормирования расхода строительных материалов.
После получения необходимого количества замеров проводится обработка данных наблюдений. Для каждого элемента операции получают ряд значений его продолжительности, т.е. хронометражный ряд. Первым этапом его обработки является исключение дефектных замеров, которые выявляются прежде всего на основе записей в наблюдательном листе об отклонениях от нормального режима работы. Затем проводится анализ хроноряда. Обычно для этого используются фактические коэффициенты устойчивости, рассчитываемые по формуле (7.2.1). Их значения сравниваются с нормативными (табл. 7.2.1). Если фактический К не больше нормативного, то хроноряд считается устойчивым, в противном случае рекомендуется исключить максимальное значение продолжительности элементов операции, а затем вновь рассчитать К. Следует отметить, что исключение дефектных замеров на основе коэффициентов устойчивости нельзя считать достаточно обоснованным.
Параметр модели — это относительно постоянная величина, включаемая в модель и рассматриваемая как свойство объекта моделирования. В свою очередь, значения параметров модели являются результатом обработки данных, полученных в процессе эксперимента или наблюдения, с помощью различных статистических методов (наименьших квадратов, максимального правдоподобия и др.). Для моделирования параметры выступают как выбираемые значения. Среди параметров выделяются такие, которые изменяют содержание модели, так называемые управляющие параметры. [c.429]
Обработка результатов замеров времени Использовать математические методы обработки результатов замеров времени с применением ЭВМ и элементами математической статистики При определении норм времени и выработки учитывать действие факторов технического переоснащения оборудования, квалификацию работников производства, занятых данной технологической операцией Листы наблюдений после предварительной обработки инженерами-нормировщиками передаются в ИВЦ для их обработки Создать в ИВЦ массив НСИ по трудоемкости технологических операций. Результаты обследования обрабатываются в ИВЦ. Результатом обработки являются варианты норм времени и выработки в конкретных условиях производства
[c.280]
Результаты обследования обрабатываются в ИВЦ. Результатом обработки являются варианты норм времени и выработки в конкретных условиях производства
[c.280]
Все методы исследования затрат рабочего времени включают следующие основные этапы подготовка к наблюдению, его проведение, обработка данных, анализ результатов и подготовка организационно-технических предложений в соответствии с целью проводимых наблюдений. Содержание работ по каждому этапу зависит от метода исследования затрат рабочего времени. [c.315]
СТАТИСТИКА ЦЕН —отрасль статистики, в задачи к-рой входит сбор и обработка данных о ценах, ценообразовании и тарифах. Методы статистич. анализа применяются с целью изучения цен и тарифов в их взаимосвязи, выяснения их влияния на выполнение производственного плана, уровень себестоимости и рентабельности предприятий, на доходы государственного бюджета, развитие товарооборота и улучшение ассортимента товаров. Большое значение имеет С. ц. для изучения роли цены в исчислении объемов валовой и товарной продукции, товарооборота, в распределении общественного продукта и национального дохода.
В первой главе рассматриваются задачи и организация статистики и экономического анализа в стране. Две последующие главы, посвященные изложению основ теории сбора данных, их сводки и группировки и простейших методов анализа, позволяют слушателям правильно использовать результаты статистического наблюдения и обработки данных, овладеть важнейшими приемами работы с цифрами. Здесь даются также понятия методов выборочного наблюдения, анализа вариации и связи. [c.4]
Методы принятия решений в условиях риска разрабатываются и обосновываются также и в рамках так называемой теории статистических решений. Теория статистических решений является теорией проведения статистических наблюдений, обработки этих наблюдений и их использования. Как известно, задачей экономического исследования является уяснение природы экономического объекта, раскрытие механизма взаимосвязи между важнейшими его переменными.
На предприятиях широко распространена самофотография рабочего времени. При определенной предварительной подготовке этот метод позволяет охватить наблюдением практически все предприятие и за короткий срок (два-три дня с обработкой данных) получить информацию об основных потерях рабочего времени. Пользуясь этим методом, рабочий (работник), не отвлекаясь от основной работы, отмечает [c.20]
Для определения норм труда вспомогательных рабочих чаще всего используют косвенные методы, с помощью которых устанавливают нормы труда не по трудоемкости конкретных работ в конкретных условиях, а по факторам, косвенно влияющим на затраты труда соответствующей группы рабочих. Зависимость нормы труда от этих факторов определяют путем статистической обработки данных планово-учетной документации и результатов наблюдений по группе представителей цехов (участков) различных предприятий.
[c.249]
Зависимость нормы труда от этих факторов определяют путем статистической обработки данных планово-учетной документации и результатов наблюдений по группе представителей цехов (участков) различных предприятий.
[c.249]
В отличие от затрат времени по основным производственным работам, результаты наблюдений по которым обрабатывают, как правило, графоаналитическим методом, при обработке материалов наблюдений и данных оперативного и технического учета о затратах рабочего времени по обслуживающим процессам для вывода эмпирических зависимостей чаще применяют корреляционный анализ. [c.145]
При исследовании социально-экономической структуры народного хозяйства и социалистического общества в целом экономическая статистика базируется на основных положениях общей теории статистики и методах ее. В этой связи необходимо выделить статистическое наблюдение, программу и научную организацию его методы обработки и сводки массовых данных, полученных в результате реализации соответствующей программы наблюдения методы анализа научно разработанных данных. [c.20]
[c.20]
Обработка результатов наблюдений. Данный этап работы по разработке норм затрат труда выполняется математическими методами и заключается а) в очистке хронометражных рядов [c.82]
В практике расчета ущерба приходится сталкиваться с большим числом условностей, значительно обедняющих реальное содержание итогового результата. Основным методом определения ущерба является метод прямого счета, предполагающий непосредственное обследование реципиентов. Другие методы в той или иной степени базируются на нем. Методом прямого счета фактически производится фиксация конкретного состояния, т. е. определение размера ущерба, который потерпело народное хозяйство за определенный промежуток времени на данной конкретной территории. Но этого недостаточно для экономического обоснования решения о проведении природоохранного мероприятия. Необходим расчет предотвращенного ущерба, а следовательно, нужно оценить ущерб в гипотетической ситуации, т. е. в ситуации, которая сложилась бы, если бы природоохранное мероприятие было проведено.
Статистика имеет свои методы получения и обработки данных учета, а именно массовое наблюдение, группировка, обработка, средние числа, индексы, анализ и др. [c.11]
Рассмотрим это на примере. Для правильного использования рабочей силы предприятию надо знать количество рабочих по профилям. Для этого в оперативном учете ежедневно отмечается количество рабочих, явившихся на работу. Статистика пользуется этими данными учета — это метод массового наблюдения. Статистика ведет подсчет рабочих по профессиям — это метод группировки. Периодически, допустим ежемесячно, данные наблюдения и группировки статистика располагает по месяцам в ряды и на каждое первое число месяца производит сравнение количества рабочих в данном месяце с количеством рабочих на начало года — это метод обработки. Полученные сведения о количестве рабочих по профессиям записываются в специальную форму
[c.12]
Периодически, допустим ежемесячно, данные наблюдения и группировки статистика располагает по месяцам в ряды и на каждое первое число месяца производит сравнение количества рабочих в данном месяце с количеством рабочих на начало года — это метод обработки. Полученные сведения о количестве рабочих по профессиям записываются в специальную форму
[c.12]
Фотография рабочего дня, особенно если она не индивидуальная, трудоемка. Поэтому в последнее время широкое распространение получил метод моментных наблюдений. При этом методе наблюдатель обходит рабочие места по заранее составленному маршруту, включающему фиксируемые точки. Состояние и содержание трудового процесса фиксируются в определенный момент. Число замеров (моментов) определяется по формулам математической статистики и достаточно велико. Метод основан на положениях теории вероятности, согласно которой вероятность повторения того или иного элемента во времени в период наблюдения прямо пропорциональна его продолжительности и обратно пропорциональна длительности наблюдения. Наблюдатель фиксирует момент затрат времени на подготовительно-заключительную, основную и вспомогательную работу, обслуживание рабочего места, перерывы в работе и их причины. Обработка данных позволяет выявить нерационально затраченное время.
[c.78]
Наблюдатель фиксирует момент затрат времени на подготовительно-заключительную, основную и вспомогательную работу, обслуживание рабочего места, перерывы в работе и их причины. Обработка данных позволяет выявить нерационально затраченное время.
[c.78]
Проблема оценок особо важна в тех случаях, когда совокупность возникает только в процессе исследования. Так, весь смысл выборочных обследований состоит в том, чтобы получить на основании данных выборки оценки неизвестных величин, характеризующих генеральную совокупность. Все связанные с этим вопросы, относящиеся как к способу обработки данных выборочного наблюдения, так и к его организации, способу отбора выборочной совокупности и др., составляют объект теории выборочного метода. Если же оцениваемая величина относится не к совокупности, а к многократно измеряемому объекту, то входящие сюда вопросы рассматриваются в теории ошибок (измерения), к-рую можно считать исторически родоначальницей М. с. [c.400]
Однако, если вы собираетесь проводить какой-то анализ, вам потребуется более сложный способ получения и обработки данных — с использованием компьютера. Существует три основных метода наблюдения и анализа цен с помощью компьютера (1) использование своего компьютера для доступа к другому компьютеру, на котором проводится анализ (2) использование терминала (предоставляется продавцом данных), способного решать определенные задачи и связываться с главным компьютером продавца данных (3) использование вашего компьютера для загрузки данных и их анализа с помощью собственного программного обеспечения.
[c.375]
Существует три основных метода наблюдения и анализа цен с помощью компьютера (1) использование своего компьютера для доступа к другому компьютеру, на котором проводится анализ (2) использование терминала (предоставляется продавцом данных), способного решать определенные задачи и связываться с главным компьютером продавца данных (3) использование вашего компьютера для загрузки данных и их анализа с помощью собственного программного обеспечения.
[c.375]
На самой деле широкому использованию этого метода препятствует его дороговизна. Дело в том, что организация наблюдений за продажами, сбор и обработка данных требуют немалых затрат, а достижение договоренности с владельцами магазинов о проведении исследований — больших усилий исследователей и некоторого везения. Отметим этой связи, что для получения надежных результатов необходимо обследовать несколько магазинов, а само исследование затягивается на несколько месяцев. Только при таком подходе можно надеяться элиминировать влияние внешних факторов, способных сказаться на динамике продаж в одном отдельно взятом магазине, и определить закономерности, присущие всей генеральной совокупности покупателей. [c.267]
[c.267]
Бухгалтерский учет, как и любая другая наука, имеет собственный предмет, объекты наблюдения и характерные для него специфические приемы и методы регистрации, сбора, обработки, накопления и передачи данных пользователям. [c.69]
Основным и наиболее ответственным этапом разработки нормативов является обработка исходных данных, полученных путем наблюдений, и установление степени влияния на них различных факторов. При небольшом количестве факторов, влияющих на величину затрат времени (до 2—3), целесообразно использовать графоаналитический метод. При большом количестве факторов — регрессионный и дисперсионный анализ. [c.207]
Метод самофотографии рабочего времени — разновидность метода упрощенных наблюдений. Чтобы установить, сколько времени в среднем затрачивается на обработку определенного типа (вида) документов или на выполнение определенного вида работ, необходимо получить данные за достаточно продолжительный период времени. Наиболее простой способ получить такие данные — предложить служащему заполнить лист наблюдения (табл. 2.2).
[c.44]
2.2).
[c.44]
Разработка плана маркетингового исследования — сложный творческий процесс, своего рода фундамент будущего исследования. План позволяет установить рамки и основные направления всего исследования. Прежде всего нужно выбрать необходимые методы его проведения. При этом надо иметь в виду, что это не механический набор методов и приемов, а целенаправленный их выбор для решения конкретных специфических задач. Нужно определить методы и процедуры сбора первичных данных (опрос, наблюдение и т.д.), методы и средства обработки полученных данных (экономико-статистические и экономико-математические методы и т.п.), а также методы анализа и обобщения материалов (моделирование, исследование операций, деловые игры, экспертиза и др.). Затем нужно определить тип требуемой информации и источников ее получения исходя из параметров имеющихся ресурсов (информации, времени и финансовых средств), а также необходимой степени достоверности, надежности данных. Например, надежность информации — результатов анкетирования — определяется обычно размерами выборки (количеством обследуемых субъектов) и репрезентативностью группы целевому сегменту рынка. [c.22]
[c.22]
Любая единица наблюдения обладает множеством признаков. При разработке программы наблюдения следует выбрать существенные для решения задач признаки, ради которых проводится наблюдение. Для этой цели нужно знать сущность и свойства объекта наблюдения и потребности органов управления в данных о нем и исходя из них определить, какие аналитические и сводные показатели необходимы, а в соответствии с последними — какие признаки необходимо подвергнуть наблюдению и включить в программу. Следовательно, для определения программы наблюдения следует в обратном порядке мысленно совершить все этапы статистической работы определить цели и методы анализа, выявить необходимые для анализа сводки и группировки, указать потребные для них признаки объекта, подлежащего наблюдению, наконец, сформулировать вопросы о них в форме отчетности (переписном листе, анкете). Такая последовательность работ по формированию программы является условием включения в нее только всех вопросов, без ответа на которые цели статистической работы не могут быть достигнуты, и невключения в нее тех вопросов, в которых нет необходимости для решения поставленной познавательной или управленческой задачи. Если не включить в программу вопросы, без ответа на которые цель статистической работы не будет достигнута, то статистическое наблюдение окажется ненужным, а средства на его проведение будут истрачены впустую. Если же включить в программу вопросы без четкого представления о том, для чего понадобятся полученные данные, то средства на их сбор и обработку также будут затрачены неэффективно.
[c.21]
Если не включить в программу вопросы, без ответа на которые цель статистической работы не будет достигнута, то статистическое наблюдение окажется ненужным, а средства на его проведение будут истрачены впустую. Если же включить в программу вопросы без четкого представления о том, для чего понадобятся полученные данные, то средства на их сбор и обработку также будут затрачены неэффективно.
[c.21]
Нормативные наблюдения различаются не только способом их проведения, системой записи данных, но и степенью точности учета времени. В табл. 16.2 приводится систематизация нормативных наблюдений в зависимости от назначения разрабатываемых норм. Полученные данные наблюдений тщательно анализируют и очищают от случайных значений. Для обработки этих данных и определения нормативных величин широко применяют методы математи- [c.336]
МАШИННАЯ ИМИТАЦИЯ, или компьютерная имитация [simulation] — экспериментальный метод изучения экономики с помощью компьютеров. (В литературе часто в том же смысле применяется термин «имитационное моделирование», однако, по-видимому, лучше разделить значения моделирование есть разработка, конструирование модели некоторого объекта для его исследования, а имитация — один из возможных способов использования модели. ) Для имитации формируется имитационная система, включающая имитационную модель, а также программное обеспечение ЭВМ. В машину вводятся необходимые данные и ведется наблюдение за тем, как изменяются интересующие исследователя показатели они подвергаются анализу, в частности статистической обработке данных.
[c.190]
) Для имитации формируется имитационная система, включающая имитационную модель, а также программное обеспечение ЭВМ. В машину вводятся необходимые данные и ведется наблюдение за тем, как изменяются интересующие исследователя показатели они подвергаются анализу, в частности статистической обработке данных.
[c.190]
На 3-м этапе разработки проекта нормативов проводят систематизацию данных о необходимых затратах рабочего времени, полученных на различных предприятиях (цехах, рабочих местах) составление сводных балансов затрат рабочего времени по данным фотографий рабочего времени анализ выявленных вариантов выполнения работы и сопоставление их с предварительно спроектированным трудовым процессом уточнение содержания трудового процесса, методов выполнения и факторов продолжительности его обработку результатов наблюдений и вывод математических зависимостей времени выполнения работы от выявленных факторов уточнение макетов таблиц и заполнение их нормативными значениями, рассчитанными по установленным математи-
[c. 38]
38]
Большое развитие как наука и как практич. деятельность С. п. получила при Сов. власти. До Окт. революции 1917 в России сбором и обработкой статистич. данных о пром-сти занимались 3 учреждения по различным программам. В. И. Ленин писал о текущей С. п. в России …у нас имеется лишь лживая, неряшливая канцелярски-путаная статистика разных ведомств»… (Поли. собр. соч., 5 изд., т. 12, с. 354). В этих условиях большое значение имели переписи промышленности, проведённые в России в 1900 и 1908. Теоретич. основы С. п. даны в трудах В. И. Ленина им сформулированы понятия единицы наблюдения и учётной единицы в пром-сти, пром. ценза. Он дал осн. указания о методе группировок в пром-сти, о науч. применении средних в С. и., методах экономико-статистич. анализа и необходимости создания центр, органа статистик . В СССР единым руководящим органом является Управление С. п. ЦСУ СССР, разрабатывающее формы статистич. отчётности для пром. предприятий и объединении, методологию определения показателей, а также занимающееся сбором и обработкой данных с помощью ЭВМ н экономико-статистич. анализа полученных результатов. В СССР данные С. п. публикуются ежегодно в статистич. сб. Народное хозяйсгво СССР , в спец. сб. Промышленность СССР и др. Вопросам С. п. уделяется большое внимание в статистич. комиссиях ООН и СЭВ.
[c.48]
анализа полученных результатов. В СССР данные С. п. публикуются ежегодно в статистич. сб. Народное хозяйсгво СССР , в спец. сб. Промышленность СССР и др. Вопросам С. п. уделяется большое внимание в статистич. комиссиях ООН и СЭВ.
[c.48]
Говоря о методах, приемах познания и его этапах, следует иметь в виду, что исходным пунктом познания является изучение конкретной действительности, практики работы промышленных предприятий, накопление материалов, фактов, характеризующих их производственно-хозяйственную деятельность, как на основе обработки статистических данных, так и путем проведения специальных обследований, наблюдений. При этом нельзя вырывать из всей массы отдельные факты, а нужно брать их во взаимосвязи, в совокупности. Только на этом фундаменте можно выявить типичные явления, обнаружить имевшую место или возникающую закономерность. На это большое внимание обращал В. И. Ленин Чтобы это был действительно фундамент, необходимо брать не отдельные факты, а всю совокупность относящихся к рассматриваемому вопросу фактов, без единого исключения . Вместе с тем, практика не только отправной пункт исследования (познания), но и этап апробации, проверки выдвигаемых положений, методов, так как именно она — практика — критерий истины. Апро-Гация предложений должна проводиться и путем постановки специальных экспериментов, в том числе экономических. Практика, наконец,— это внедрение разработанных методов, реализация предложений.
[c.8]
Вместе с тем, практика не только отправной пункт исследования (познания), но и этап апробации, проверки выдвигаемых положений, методов, так как именно она — практика — критерий истины. Апро-Гация предложений должна проводиться и путем постановки специальных экспериментов, в том числе экономических. Практика, наконец,— это внедрение разработанных методов, реализация предложений.
[c.8]
К сожалению, успех в применении технического анализа полностью зависит от качества метода оптимизации, о которой говорилось выше. Взяв длину промежутка для скользящего среднего равной, например, 125 дням, мы тем самым неизбежно ограничиваем свой выбор среди различных характеристик временных рядов для данной базы данных. Следует понимать, что такие действия, не сопровождающиеся достаточно хорошим подтверждением, могут привести к переобучению и потере способности к обобщению. Более того, многие инвесторы считают, что ключом к успеху в инвестиционном деле является интуиция аналитика, а не применение какой-либо процедуры отбора или формулы. В связи с этим Холи и др. [136] утверждают, что хотя успехи нейронных сетей в распознавании образов и делают возможным их использование в техническом анализе, все же наиболее выигрышные приемы будут, скорее всего, разработаны самими чартистами. Высказываются также предостережения против чрезмерной предварительной обработки входных данных, и поэтому мы воздержались от сверхоптимизации данных. Для того чтобы сохранить статистическую представительность данных, мы выбрали для обучения сети недельный промежуток времени. Для 5-20-1 сети это дает примерно 10 наблюдений на один весовой коэффициент.
[c.213]
В связи с этим Холи и др. [136] утверждают, что хотя успехи нейронных сетей в распознавании образов и делают возможным их использование в техническом анализе, все же наиболее выигрышные приемы будут, скорее всего, разработаны самими чартистами. Высказываются также предостережения против чрезмерной предварительной обработки входных данных, и поэтому мы воздержались от сверхоптимизации данных. Для того чтобы сохранить статистическую представительность данных, мы выбрали для обучения сети недельный промежуток времени. Для 5-20-1 сети это дает примерно 10 наблюдений на один весовой коэффициент.
[c.213]
МАТЕМАТИЧЕСКАЯ СТАТИСТИКА (mathemati al statisti s) — раздел математики, посвященный систематизации, обработке и использованию стат данных В М с мн методы стат обработки исходных данных основываются на вероятностной природе этих данных Оси понятиями М с являются генеральная совокупность (мн-во значений случайной величины), выборка (ограниченное число наблюдений случайной величины), объем выборки (кол-во значений случайной величины в выборке), параметр положения (ср значение случайной величины), мера рассеяния (квадратный корень из дисперсии счучайной величины) и т д Одной из задач М с является построение оценок случайной величины Различают оценки точечные, интервальные, робастные (устойчивые, т е слабо реагирующие на утрату части исходных данных, засорение выборки и т п ), эффективные (имеющие ми-ним дисперсию) и др Получили развитие и нашли широкое практическое применение такие разделы М с, как дисперсионный анализ, кластерный анализ, факторный анализ, методы планирования эксперимента, приемочного контроля статистического и др
[c. 131]
131]
Хронометражные данные являются выборкой из всей статистической совокупности значений длительности той или иной операции или ее элемента. Исходя из этого, необходимое число замеров можно определить методами математической статистики. Однако эти методы не дают возможности заранее, до специальной обработки полученного хронометражного ряда, определить, достаточно ли проведено наблюдений. Поэтому на этапе подготовки к хронометраж-ным наблюдениям пользуются эмпирическими формулами расчета необходимого числа наблюдений и специальными таблицами. Одна лз таких формул, рекомендованная НИИтруда, имеет следующий вид [c.122]
Количественная обработка результатов исследования по психологии » Заказ курсовых, контрольных, дипломных работ
Использование методов математической статистики при обработке первичных эмпирических данных необходимо для повышения достоверности выводов как в научном исследовании, так и в разработке в области практической психологии. При этом не рекомендуется ограничиваться использованием таких показателей, как среднее арифметическое и проценты. Они чаще всего не дают достаточных оснований для обоснованных выводов из эмпирических данных.
Использование методов математической статистики при обработке первичных эмпирических данных необходимо для повышения достоверности выводов как в научном исследовании, так и в разработке в области практической психологии. При этом не рекомендуется ограничиваться использованием таких показателей, как среднее арифметическое и проценты. Они чаще всего не дают достаточных оснований для обоснованных выводов из эмпирических данных.
Они чаще всего не дают достаточных оснований для обоснованных выводов из эмпирических данных.
Использование методов математической статистики при обработке первичных эмпирических данных необходимо для повышения достоверности выводов как в научном исследовании, так и в разработке в области практической психологии. При этом не рекомендуется ограничиваться использованием таких показателей, как среднее арифметическое и проценты. Они чаще всего не дают достаточных оснований для обоснованных выводов из эмпирических данных. Чтобы выбрать статистические критерии и познакомиться с основами их применения для обработки эмпирических данных, можно использовать ряд пособий (например: Большее, Смирнов, 1969; Гласс, Стенли, 1976; Закс, 1976; Сосновский, 1979; Рунион, 1982; Сидоренко, 2001; Калинин, 2002; Ермолаев, 2003; Наследов, 2004). Множество критериев, приводимых обычно в учебниках по математической статистике, и сложное описание процедур их вычисления часто смущают студента, хотя значительная их часть используется достаточно редко. Каждый исследователь (и научный руководитель в том числе) выбирает статистические критерии, исходя из своих знаний, опыта, типа задачи и вида данных, которые подлежат обработке.
Каждый исследователь (и научный руководитель в том числе) выбирает статистические критерии, исходя из своих знаний, опыта, типа задачи и вида данных, которые подлежат обработке.
Как же поступить студенту? Можно положиться на опыт и советы научного руководителя (однако основательно разобравшись при этом в смысле и процедуре критерия). Можно опереться на примеры, приведенные в методических пособиях. Книги Е.В. Сидоренко (2001) и О.Ю. Ермолаева (2003) приводят примеры так называемой «ручной» обработки данных, в книгах С.И. Калинина (2002) и А.Д. Наследова (2004) даны описания статистической обработки с использованием статистических программ.
Статистические гипотезы. Выбор статистических критериев предполагает также формулировку статистических гипотез, то есть перевода экспериментальной гипотезы на язык статистики. Таким образом, статистическая гипотеза — это утверждение в отношении изучаемой переменной, сформулированное на языке математической статистики. Для этого необходимо определить математико-статистические критерии, уровни статистической значимости, которые дают основания исследователю утверждать, подтвердилась экспериментальная гипотеза или нет. На этом этапе исследования формулируются статистические гипотезы, которые конкретизируют соответствующую эмпирическую гипотезу на уровне математических критериев значимости. Эмпирическая (экспериментальная) гипотеза воплощается в процедуре статистической интерпретации данных. Эта процедура сводима к оценке сходств и различий. При проверке статистических гипотез используются два понятия:
На этом этапе исследования формулируются статистические гипотезы, которые конкретизируют соответствующую эмпирическую гипотезу на уровне математических критериев значимости. Эмпирическая (экспериментальная) гипотеза воплощается в процедуре статистической интерпретации данных. Эта процедура сводима к оценке сходств и различий. При проверке статистических гипотез используются два понятия:
Н(1) (гипотеза о различии) и
Н(0) (гипотеза о сходстве).
Подтверждение первой гипотезы свидетельствует о верности статистического утверждения Н(1), а второй — о принятии утверждения Н(0) — об отсутствии различий.
После проведения конкретного эксперимента проверяются многочисленные статистические гипотезы, поскольку в каждом психологическом исследовании регистрируется не один, а множество поведенческих параметров. Каждый параметр характеризуется несколькими статистическими мерами: центральной тенденции, изменчивости, распределения. Кроме того, можно вычислить меры связи параметров и оценить значимость этих связей.
Таким образом, экспериментальная гипотеза служит для организации и проведения эмпирического исследования, а статистическая — для организации процедуры сравнения регистрируемых параметров. Статистическая гипотеза необходима на этапе математической интерпретации данных эмпирических исследований. Естественно, большое количество статистических гипотез необходимо для подтверждения или опровержения экспериментальной (эмпирической) гипотезы.
Выбирать математические методы обработки эмпирических данных нужно в процессе планирования исследования. Выбор метода математической обработки полученных эмпирических данных — очень важная и ответственная часть исследования. И делать это лучше до того, как получены данные. При планировании исследования необходимо заранее продумать, какие эмпирические показатели будут регистрироваться, с помощью каких методов будут обрабатываться и какие выводы при разных результатах обработки можно будет сделать. Полезным руководством при этом может стать классификация задач и методов их решения, которую приводит Е. В. Сидоренко (2001, с. 34).
В. Сидоренко (2001, с. 34).
Следует идентифицировать тип переменных и шкалу измерения. При выборе математико-статистического критерия нужно, прежде всего, идентифицировать тип переменных (признаков) и шкалу, которая использовалась при измерении психологических показателей и других переменных (возраст, состав семьи, уровень образования).
В качестве переменных могут выступать любые показатели, которые можно сравнивать друг с другом (то есть измерять). Это может быть время выполнения задания, количество ошибок, уровень самооценки, количество правильно решенных задач и качественные особенности их выполнения, личностные показатели, получаемые в психологических тестах, и др. Порой для студентов представляет трудность выделение переменных в работах по практической психологии, где возможности использования традиционных и стандартизированных психологических тестов (с которыми обычно ассоциируется проблема измерения) ограничены. Следует иметь в виду, что в области практической психологии могут широко использоваться номинативные и порядковые шкалы. Речевые высказывания клиента, виды поведенческих реакций, улыбки, взгляды, — все это может рассматриваться в качестве переменных. Главное — иметь четкие и ясные критерии их отнесения к тому или иному типу в зависимости от поставленных гипотез и задач.
Речевые высказывания клиента, виды поведенческих реакций, улыбки, взгляды, — все это может рассматриваться в качестве переменных. Главное — иметь четкие и ясные критерии их отнесения к тому или иному типу в зависимости от поставленных гипотез и задач.
Нужно учитывать тип распределения данных при выборе статистического критерия. При выборе математико-статистического критерия следует также ориентироваться на тип распределения данных, который получился в исследовании. Параметрические критерии используются в том случае, когда распределение полученных данных рассматривается как нормальное. Нормальное распределение с большей вероятностью (но не обязательно) получается при выборках более 100 испытуемых (может получиться и при меньшем количестве, а может не получиться и при большем). При использовании параметрических критериев необходима проверка нормальности распределения.
Для непараметрических критериев тип распределения данных не имеет значения. При небольших объемах выборки испытуемых, используемой обычно в курсовой или дипломной работе, целесообразно выбрать непараметрические критерии, которые дают большую достоверность выводам, независимо от того, получено ли в исследовании нормальное распределение данных. В некоторых случаях статистически обоснованные выводы могут быть сделаны даже при выборках в 5-10 испытуемых.
В некоторых случаях статистически обоснованные выводы могут быть сделаны даже при выборках в 5-10 испытуемых.
Основные типы исследовательских задач с точки зрения статистических процедур обработки данных. Большинство психологических работ сводятся к нескольким типам исследовательских задач, которые и предопределяют тип математико-статистического критерия.
1. Во многих исследованиях осуществляется поиск различий в психологических показателях у испытуемых, имеющих те или иные особенности. При обработке соответствующих данных могут использоваться критерии для выявления различий в уровне исследуемого признака или в его распределении. Для определения значимости различий в проявлении признака в психологических исследованиях часто используются такие показатели, как парный критерий Вилкоксона, U-критерий Манна-Уитни, критерий хи-квадрат (x2), точный критерий Фишера, биномиальный критерий.
2. Во многих исследованиях осуществляется поиск взаимосвязи психологических показателей у одних и тех же испытуемых. Для обработки соответствующих данных могут использоваться коэффициенты корреляции. Связь величин друг с другом и их зависимость часто характеризуются коэффициентом линейной корреляции Пирсона и коэффициентом ранговой корреляции Спирмена.
Для обработки соответствующих данных могут использоваться коэффициенты корреляции. Связь величин друг с другом и их зависимость часто характеризуются коэффициентом линейной корреляции Пирсона и коэффициентом ранговой корреляции Спирмена.
3. Выявление структуры данных (и соответственно структуры изучаемой психологической реальности), а также их взаимосвязи выявляется факторным анализом.
4. Во многих исследованиях интерес представляет анализ изменчивости признака под влиянием каких-либо контролируемых факторов, или, другими словами, оценка влияния разных факторов на изучаемый признак. Для математической обработки данных в таких задачах может использоваться U-критерий Манна-Уитни, критерий Краскела-Уоллиса, Т-критерий Вилкоксона, критерий x2 Фридмана. Однако для исследования влияния нескольких факторов на изучаемый параметр (а тем более их взаимовлияния) полезнее может оказаться дисперсионный анализ. Исследователь исходит из предположения, что одни переменные могут рассматриваться как причины, а другие как следствия. Переменные первого рода считаются факторами, а переменные второго рода — результативными признаками. В этом отличие дисперсионного анализа от корреляционного, в котором предполагается, что изменения одного признака просто связаны с определенными изменениями другого (Сидоренко, 2001, с. 225).
Переменные первого рода считаются факторами, а переменные второго рода — результативными признаками. В этом отличие дисперсионного анализа от корреляционного, в котором предполагается, что изменения одного признака просто связаны с определенными изменениями другого (Сидоренко, 2001, с. 225).
5. Во многих исследованиях выявляется значимость изменений (сдвига) каких-либо психологических, поведенческих параметров и проявлений за определенный промежуток времени в определенных условиях (например, в условиях коррекционного воздействия). Формирующие эксперименты в практической психологии решают именно эту задачу. Для обработки соответствующих данных могут использоваться коэффициенты оценки достоверности сдвига в значениях исследуемого признака. Для этого часто применяются критерии знаков, Т-критерий Вилкоксона.
Важно обратить внимание на ограничения, которые имеет каждый критерий. Если один критерий не подходит для анализа имеющихся данных, всегда можно найти какой-либо другой, возможно, изменив тип представления самих данных. Прежде чем обрабатывать эмпирические данные, полезно проверить, существуют ли в пособии, которым вы пользуетесь, критические значения, соответствующие количеству и типу ваших данных. В противном случае вас может ждать разочарование, когда ваши подсчеты окажутся напрасными по причине отсутствия в таблице критических значений при объеме выборки, которая у вас была.
Прежде чем обрабатывать эмпирические данные, полезно проверить, существуют ли в пособии, которым вы пользуетесь, критические значения, соответствующие количеству и типу ваших данных. В противном случае вас может ждать разочарование, когда ваши подсчеты окажутся напрасными по причине отсутствия в таблице критических значений при объеме выборки, которая у вас была.
После знакомства с процедурой вычисления критерия можно провести «ручную» обработку данных или воспользоваться статистической программой персонального компьютера. Для компьютерной обработки одни психологи предпочитают пакет статистических программ SPSS, другие — программу Statistica. Студенты-психологи предпочитают SPSS, прежде всего, потому, что в последние годы опубликованы хорошие руководства по его применению (Калинин, 2002; Наследов, 2004).
Методы математической обработки данных важно использовать и для анализа результатов инновационной практической психологической работы: психотерапии, консультирования, развивающей психологической работы. Для этого необходимо регистрировать конкретные психологические и поведенческие показатели участников исследования «до» и «после» курса психологической помощи, которые могут статистически обрабатываться и использоваться для подтверждения эффективности курса занятий. Применение математико-статистических критериев для проверки значимости изменений придает доказательность выводам такой работы.шаблоны для dle 11.2
Для этого необходимо регистрировать конкретные психологические и поведенческие показатели участников исследования «до» и «после» курса психологической помощи, которые могут статистически обрабатываться и использоваться для подтверждения эффективности курса занятий. Применение математико-статистических критериев для проверки значимости изменений придает доказательность выводам такой работы.шаблоны для dle 11.2
Научный вебинар «Методы обработки полуструктурированных текстов для задач классификации и генерации контента»
Вебинар состоялся 24 сентября 2020 г. В этот раз мы обсуждали методы обработки полуструктурированных текстов для задач классификации и генерации контента.
Во время данного вебинара были рассмотрены следующие вопросы:
Методы обработки полуструктурированных текстов для задач классификации и генерации контента
Генерация какого-либо текстового контента требует решения не только самой задачи генерации, но и первичного анализа имеющейся информации, которая зачастую сама представлена в текстовом виде. Последнее приводит к необходимости разработки sequence-to-sequence методов и подходов обработки данных. Ситуацию может усложнять большой объем входных данных, из которого нужно выделить действительно существенные части, обработав которые можно будет произвести необходимый контент. В свою очередь, это влечет необходимость разработки целых каскадов из вспомогательных и основных методов для получения хорошего результата. В докладе будут рассмотрены современные нейросетевые методы генерации текстового контента на примерах задач генерации рекламы и вопросно-ответных систем.
Последнее приводит к необходимости разработки sequence-to-sequence методов и подходов обработки данных. Ситуацию может усложнять большой объем входных данных, из которого нужно выделить действительно существенные части, обработав которые можно будет произвести необходимый контент. В свою очередь, это влечет необходимость разработки целых каскадов из вспомогательных и основных методов для получения хорошего результата. В докладе будут рассмотрены современные нейросетевые методы генерации текстового контента на примерах задач генерации рекламы и вопросно-ответных систем.
Докладчик:
Николай Бутаков, руководитель научной группы анализа социальных медиа в НЦКР Университета ИТМО
Оптимизация тематических моделей в рамках эксплоративного анализа и представления текстовых данных.
Тематическое моделирование — популярный метод для обработки текстов с целью эксплоративного анализа, позволяющий получить интерпретируемое представление документа без дополнительных затрат на разметку текста. Полученные распределения по темам могут использоваться как базис для обучения конечным задачам, например классификации. Однако, при работе с разнообразными наборами данных для получения желаемого качества требуется использование сложных моделей с большим числом регуляризаторов. Обилие настраиваемых параметров, а также необходимость их применения в определенном порядке приводит к возникновению задачи оптимизации стратегии построения тематических моделей.
Полученные распределения по темам могут использоваться как базис для обучения конечным задачам, например классификации. Однако, при работе с разнообразными наборами данных для получения желаемого качества требуется использование сложных моделей с большим числом регуляризаторов. Обилие настраиваемых параметров, а также необходимость их применения в определенном порядке приводит к возникновению задачи оптимизации стратегии построения тематических моделей.
Докладчик:
Мария Ходорченко, научный сотрудник группы инфраструктуры больших данных и анализа публичных источников в НЦКР Университета ИТМО
Методы работы с короткими (и не только) текстовыми данными без разметки с помощью нейронных сетей для автоклассификации текста.
Рост числа данных приводит к увеличения числа подзадач в работе с текстовыми данными, например, возникают новые доменные области. Обычно под эти задачи нет дополнительной разметки и необходимы методы, не требующие её. Применение тематических моделей в таких ситуациях не всегда подходит — тексты могут быть короткими, кроме того, классические тематические модели не учитывают связи между словами и не позволяют определять какие части текста соответствует выделенным тематикам. Последние разработки в области нейронных сетей для текстовых данных позволяют исправить эти недостатки.
Обычно под эти задачи нет дополнительной разметки и необходимы методы, не требующие её. Применение тематических моделей в таких ситуациях не всегда подходит — тексты могут быть короткими, кроме того, классические тематические модели не учитывают связи между словами и не позволяют определять какие части текста соответствует выделенным тематикам. Последние разработки в области нейронных сетей для текстовых данных позволяют исправить эти недостатки.
Докладчик:
Тимур Сохин, научный сотрудник группы инфраструктуры больших данных и анализа публичных источников в НЦКР Университета ИТМО
СПИСОК ЛИТЕРАТУРЫ1. Современные методы измерения, обработки и интерпретации электромагнитных данных. |
 Электромагнитное зондирование Земли и сейсмичность / Под ред. В.В. Спичака. — М.: КД Либроком, 2009. — 304 c.
Электромагнитное зондирование Земли и сейсмичность / Под ред. В.В. Спичака. — М.: КД Либроком, 2009. — 304 c. А. Большаков, Р.Н. Каримов. — М.: ГЛТ , 2014. — 520 c.
А. Большаков, Р.Н. Каримов. — М.: ГЛТ , 2014. — 520 c. В. Зенков, О.А. Поляков, В.Е. Юрченко. — М.: Ленанд, 2013. — 268 c.
В. Зенков, О.А. Поляков, В.Е. Юрченко. — М.: Ленанд, 2013. — 268 c. В. Клепиков, А.М. Кузнецов, А.С. Лобанов [и др.]. — М.: Форум, 2007. — 104 c.
В. Клепиков, А.М. Кузнецов, А.С. Лобанов [и др.]. — М.: Форум, 2007. — 104 c. В. Крянев, Г.В. Лукин. — М.: Физматлит, 2006. — 216 c.
В. Крянев, Г.В. Лукин. — М.: Физматлит, 2006. — 216 c. — М.: МЕДпресс-информ, 2006. — 32 c.
— М.: МЕДпресс-информ, 2006. — 32 c. А. Дистанционное зондирование Методы и модели обработки изображений / Р.А. Шовенгердт. — М.: Техносфера, 2010. — 560 c.
А. Дистанционное зондирование Методы и модели обработки изображений / Р.А. Шовенгердт. — М.: Техносфера, 2010. — 560 c.Capitols | Капитолс — Большие данные: инструменты и методы обработки
В конкурентном мире, вынуждающем соперничающие компании постоянно снижать маржинальность, бизнес рассматривает большие данные как возможность получить абсолютное оружие в борьбе за выживание. Что же такое большие данные и почему о них надо волноваться?
Что же такое большие данные и почему о них надо волноваться?
Термин «большие данные» (Big Data) означает набор инструментов и методов обработки структурированных и неструктурированных данных огромных размеров, находящихся в разных источниках, а также получаемый результат такой обработки. Как правило, размер обрабатываемых данных может начинаться от террабайт и выше (1 TB = 1,000 GB).
По данным исследования IDC Digital Universe, размер накапливаемого объема информации с каждым годом растет экспоненциально. В случае, если вовремя не применить необходимые инструменты по обработке таких данных, это может привести к потере ценной информации и, возможно, краху компании.
Также, согласно исследованиям компании IDC, в большинстве предприятий используется как минимум пять различных систем для автоматизации бизнес процессов. В некоторых предприятиях могут использоваться несколько десятков, а иногда, и несколько сотен различных источников данных.
Как собрать, подготовить, отфильтровать и систематизировать большие массивы данных разного формата и получить необходимую информацию в реальном времени?
Для решения таких задач существуют современные и эффективные программные средства, позволяющие самостоятельно и мгновенно агрегировать и обработать большие массивы различных типов данных из разных источников без привлечения ИТ специалистов.
Компания Capitols предлагает уникальное решение Alteryx. Это высокотехнологичная платформа для поиска, смешивания, фильтрации, совместного исследования, масштабирования и анализа данных методом визуального программирования. Обладает 250+ code-free, code-friendly и drag-and-drop инструментами, которые позволяют самостоятельно и без знаний программирования исследовать большие массивы данных.
Методы воспроизведения и обработки данных — Студопедия
Естественные методы. Методы, основанные на органах чувств. Логическое мышление. Воображение, сравнение, сопоставление, анализ, прогнозирование и т.п.
Аппаратные методы. Аппаратные методы – это всегда устройства (приборы). Магнитофоны, телефоны, микроскопы, видеомагнитофоны и т.д. С точки зрения информатики эти устройства выполняют общую функцию – преобразуют данные из формы, недоступной для естественных методов человека, в форму, доступную для них. Не всегда одни устройства могут обрабатывать данные созданные другими приборами. В таких случаях применяют специальные устройства преобразования данных, и говорят не о преобразовании формы данных, а о преобразовании их формата (модемы, бытовые видеокамеры).
В таких случаях применяют специальные устройства преобразования данных, и говорят не о преобразовании формы данных, а о преобразовании их формата (модемы, бытовые видеокамеры).
Программные методы. Широкое внедрение средств вычислительной техники позволяет автоматизировать обработку самых разных видов данных с помощью компьютера. Компьютер – это прибор особого типа, в котором одновременно сочетаются аппаратные и программные методы обработки и представления информации. Эти методы составляют предметную область информатики.
Если предположить, что информация – это динамический объект, не существующий в природе сам по себе, а образующийся в ходе взаимодействия данных и методов, и существующий столько, сколько длится это взаимодействие, а все остальное время пребывающий в виде данных, то можно дать такое определение:
Информация — это продукт взаимодействия данных и методов, рассмотренный в контексте этого взаимодействия.
Контекстным (адекватным) считается тот метод, который является общепринятым для работы с данными определенного типа. Этот метод должен быть известен как создателю данных, так и потребителю информации.
Этот метод должен быть известен как создателю данных, так и потребителю информации.
Для графических данных (иллюстраций) контекстным является метод наблюдения, основанный на зрении. В этом случае имеется в виду визуальная или графическая информация. Для текстовых данных подразумевается контекстный метод чтения, основанный на зрении, знании азбуки и языка. В этом случае говорят о текстовой информации.
Для данных, представленных в виде радиоволн, контекстными являются аппаратные методы преобразования данных и потребления информации с помощью радиоприемника или телевизора. Поэтому часто используются понятия телевизионная информация, информационная программа, информационный выпуск и т.п.
Для данных, хранящихся в компьютере, передающихся по сетям, контекстными являются аппаратные и программные методы вычислительной техники. Их еще называют средствами информационных технологий, которые входят в предметную область информатики. В этом случае используется понятие компьютерной информации.
Материалы 18-й Всероссийской открытой конференции «Современные проблемы дистанционного зондирования Земли из космоса»
Материалы 18-й Всероссийской открытой конференции «Современные проблемы дистанционного зондирования Земли из космоса»XVIII.A.261
Фурман Ю.В. (1), Скрипачев В.О. (2), Жуков А.О. (1,3,4), Окунев Е.В. (1)
(1) АО «Особое конструкторское бюро Московского энергетического института», Москва, Россия
(2) Российский технологический университет (МИРЭА), Москва, Россия
(3) Экспертно-аналитический центр, Москва, Россия
(4) Институт астрономии Российской академии наук, Москва, Россия
В данном докладе рассмотрены современные методы обработки данных, полученных космическими аппаратами дистанционного зондирования Земли (КА ДЗЗ): автоматической сегментации, спектрального разделения, выделения с применением обучаемой искусственной нейронной сети и др. Изучены актуальные проблемы и тенденции развития рассмотренных методов.
Техническое совершенствование целевой аппаратуры КА ДЗЗ, наращивание орбитальной группировки и расширение спектра решаемых ими прикладных задач приводят к стремительному росту объема поступающих данных, требующих дальнейшей обработки, анализа и интерпретации. Это приводит к повышению требований к быстродействию и качеству методов обработки данных, полученных КА ДЗЗ.
Для решения данных задач в современных методах обработки данных ДЗЗ нашли широкое применение самые актуальные алгоритмы и технологии, такие как параллельное и распределенные вычисление, искусственные нейронные сети, программируемые логические интегральные схемы и др. Благодаря этому повышается быстродействие выполнения прикладных задач, появляется возможность применения более требовательных к производительности методов, повышается качество и точность получаемых результатов.
Работа подготовлена при финансовой поддержке гранта Президента (проект НШ-2686.2020.8 «Модели, методы и средства получения и обработки информации о космических объектах в широком спектральном диапазоне электромагнитных волн»).
Ключевые слова: Дистанционное зондирование Земли, обработка данных, распознавание, искусственная нейронная сеть
Литература:
- Современные технологии обработки данных дистанционного зондирования Земли / Под. ред В.В. Еремеева. М.: ФИЗМАТЛИТ, 2015.
- Абрамов Н. С. и др. Современные методы интеллектуальной обработки данных ДЗЗ // Программные системы: теория и приложения, т. 9, №4(39), с.417-442, 2018.
- Ращупкин А. В. Методы обработки данных дистанционного зондирования для повышения качества выходных изображений // Вестник Самарского университета. Аэрокосмическая техника, технологии и машиностроение, №2(22), с.124-133, 2010.
Ссылка для цитирования: Фурман Ю.В., Скрипачев В.О., Жуков А.О., Окунев Е.В. Современные методы обработки данных дистанционного зондирования Земли // Материалы 18-й Всероссийской открытой конференции «Современные проблемы дистанционного зондирования Земли из космоса». Москва: ИКИ РАН, 2020. C. 53. DOI 10.21046/18DZZconf-2020a
Методы и алгоритмы обработки спутниковых данных
53
Типы, методы, этапы цикла обработки данных
Независимо от того, используете ли вы Интернет для изучения определенной темы, завершения финансовых операций в Интернете, заказа еды и т. Д., Данные генерируются каждую секунду. Использование социальных сетей, онлайн-покупок и сервисов потокового видео увеличило объем данных. По оценкам исследования Domo, в 2020 году для каждого человека на планете каждую секунду создается 1,7 МБ данных. И для того, чтобы использовать и получить представление о таком огромном количестве данных, в игру вступает обработка данных.
Д., Данные генерируются каждую секунду. Использование социальных сетей, онлайн-покупок и сервисов потокового видео увеличило объем данных. По оценкам исследования Domo, в 2020 году для каждого человека на планете каждую секунду создается 1,7 МБ данных. И для того, чтобы использовать и получить представление о таком огромном количестве данных, в игру вступает обработка данных.
Что такое обработка данных?
Данные в необработанном виде бесполезны для какой-либо организации. Обработка данных — это метод сбора необработанных данных и их преобразования в полезную информацию. Обычно это выполняется поэтапно группой специалистов по обработке данных и инженеров по данным в организации. Необработанные данные собираются, фильтруются, сортируются, обрабатываются, анализируются, сохраняются и затем представляются в читаемом формате.
Обработка данных имеет решающее значение для организации более эффективных бизнес-стратегий и повышения их конкурентоспособности.Преобразуя данные в читаемый формат, такой как графики, диаграммы и документы, сотрудники всей организации могут понимать и использовать данные.
Программа последипломного образования в области инженерии данных
Ваш путь к курсу ExpertView по разработке данныхЦикл обработки данных
Цикл обработки данных состоит из серии этапов, на которых необработанные данные (входные данные) передаются в процесс (ЦП) для получения практических сведений (выход). Каждый шаг выполняется в определенном порядке, но весь процесс повторяется циклически.Выходные данные первого цикла обработки данных могут быть сохранены и использованы в качестве входных данных для следующего цикла.
Рис: Цикл обработки данных (источник)
Как правило, цикл обработки данных состоит из шести основных этапов:
Шаг 1: Сбор
Сбор необработанных данных — это первый шаг цикла обработки данных. Тип собранных необработанных данных имеет огромное влияние на получаемые результаты. Следовательно, необработанные данные следует собирать из определенных и точных источников, чтобы последующие результаты были достоверными и пригодными для использования. Необработанные данные могут включать денежные показатели, файлы cookie веб-сайта, отчеты о прибылях и убытках компании, поведение пользователей и т. Д.
Необработанные данные могут включать денежные показатели, файлы cookie веб-сайта, отчеты о прибылях и убытках компании, поведение пользователей и т. Д.
Шаг 2: Подготовка
Подготовка или очистка данных — это процесс сортировки и фильтрации необработанных данных для удаления ненужных и неточных данных. Необработанные данные проверяются на наличие ошибок, дублирования, просчетов или отсутствующих данных и преобразуются в подходящую форму для дальнейшего анализа и обработки. Это сделано для того, чтобы в блок обработки поступали данные только самого высокого качества.
Шаг 3: Введите
На этом этапе необработанные данные преобразуются в машиночитаемую форму и передаются в блок обработки. Это может быть в форме ввода данных через клавиатуру, сканер или любой другой источник ввода.
Шаг 4: Обработка данных
На этом этапе необработанные данные подвергаются различным методам обработки данных с использованием алгоритмов машинного обучения и искусственного интеллекта для получения желаемого результата. Этот шаг может незначительно отличаться от процесса к процессу в зависимости от источника обрабатываемых данных (озера данных, онлайн-базы данных, подключенные устройства и т. Д.) и предполагаемое использование вывода.
Этот шаг может незначительно отличаться от процесса к процессу в зависимости от источника обрабатываемых данных (озера данных, онлайн-базы данных, подключенные устройства и т. Д.) и предполагаемое использование вывода.
Шаг 5: Вывод
Данные, наконец, передаются и отображаются пользователю в удобочитаемой форме, такой как графики, таблицы, векторные файлы, аудио, видео, документы и т. Д. Эти выходные данные могут быть сохранены и далее обработаны в следующем цикле обработки данных.
Шаг 6: Хранение
Последним этапом цикла обработки данных является хранение, где данные и метаданные хранятся для дальнейшего использования. Это обеспечивает быстрый доступ к информации и ее извлечение, когда это необходимо, а также позволяет напрямую использовать ее в качестве входных данных в следующем цикле обработки данных.
Типы обработки данных
Существуют разные типы обработки данных в зависимости от источника данных и шагов, предпринимаемых блоком обработки для генерации вывода.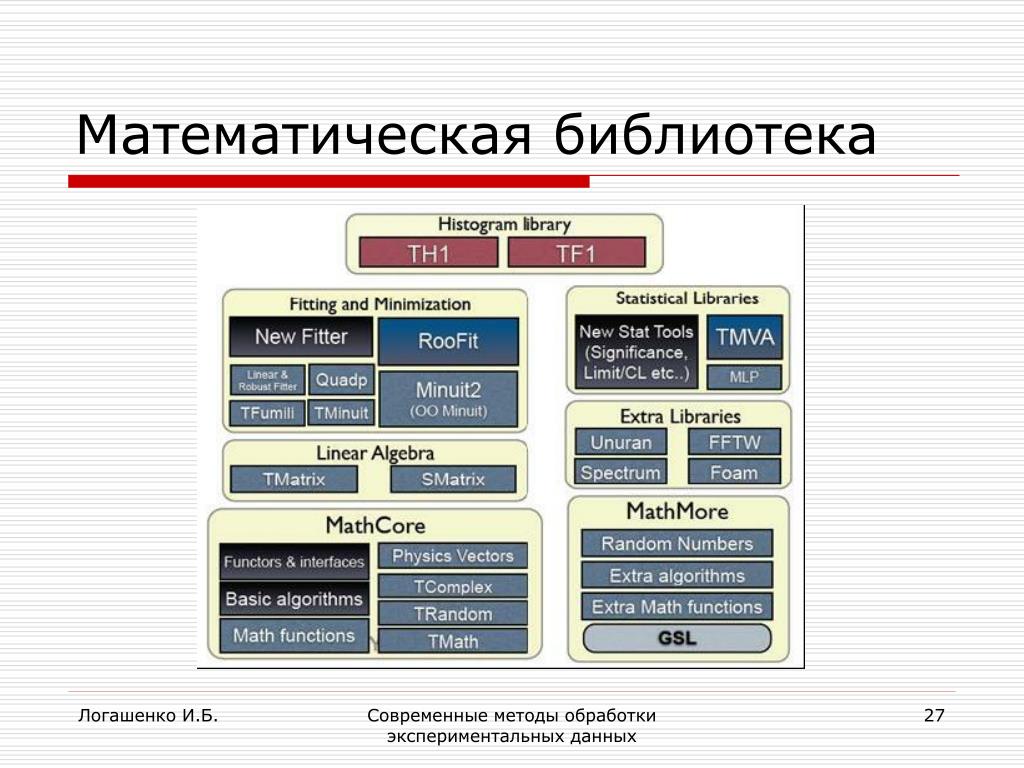 Не существует универсального метода, который можно было бы использовать для обработки необработанных данных.
Не существует универсального метода, который можно было бы использовать для обработки необработанных данных.
Тип | использует |
Пакетная обработка | Данные собираются и обрабатываются партиями. Используется для больших объемов данных. Например: система расчета заработной платы |
Обработка в реальном времени | Данные обрабатываются в течение нескольких секунд после ввода. Используется для небольших объемов данных. Например: снятие денег в банкомате |
Онлайн-обработка | Данные автоматически загружаются в ЦП, как только становятся доступными. Используется для непрерывной обработки данных. Например: сканирование штрих-кода |
Многопроцессорность | Данные разбиваются на кадры и обрабатываются с использованием двух или более процессоров в одной компьютерной системе. Например: прогноз погоды |
Разделение времени | Распределяет ресурсы компьютера и данные во временных интервалах между несколькими пользователями одновременно. |
 Также известна как параллельная обработка.
Также известна как параллельная обработка.Руководство по собеседованию с Data Engineer
Вот как пройти собеседование при первом запускеЗагрузить сейчасМетоды обработки данных
Существует три основных метода обработки данных — ручной, механический и электронный.
Ручная обработка данных
В этом методе обработки данных данные обрабатываются вручную. Весь процесс сбора данных, фильтрации, сортировки, вычислений и других логических операций выполняется с участием человека без использования каких-либо других электронных устройств или программного обеспечения для автоматизации. Это недорогой метод, не требующий почти никаких инструментов, но он дает большое количество ошибок, высокие затраты на рабочую силу и много времени.
Обработка механических данных
Данные обрабатываются механически с помощью устройств и машин.Это могут быть простые устройства, такие как калькуляторы, пишущие машинки, печатный станок и т. Д. С помощью этого метода можно выполнить простые операции обработки данных. В нем гораздо меньше ошибок, чем при ручной обработке данных, но увеличение объема данных сделало этот метод более сложным и трудным.
Электронная обработка данных
Данные обрабатываются с использованием современных технологий с использованием программного обеспечения и программ обработки данных. Программному обеспечению предоставляется набор инструкций для обработки данных и вывода результатов.Этот метод является наиболее дорогим, но обеспечивает максимальную скорость обработки при высочайшей надежности и точности вывода.
Примеры обработки данных
Обработка данных происходит в нашей повседневной жизни независимо от того, осознаем мы это или нет. Вот несколько реальных примеров обработки данных:
- Программное обеспечение для торговли акциями, которое преобразует миллионы данных об акциях в простой график
- Компания электронной торговли использует историю поиска клиентов, чтобы рекомендовать аналогичные продукты
- Компания цифрового маркетинга использует демографические данные о людях для разработки стратегии кампаний с учетом местоположения
- Беспилотный автомобиль использует данные от датчиков в реальном времени, чтобы определять, есть ли на дороге пешеходы и другие автомобили
Хотите начать свою карьеру в качестве инженера по большим данным? Пройдите курс обучения инженеров по большим данным и получите сертификат.

Вот что вы можете сделать дальше
Data содержит много полезной информации для организаций, исследователей, учреждений и отдельных пользователей. С увеличением количества данных, генерируемых каждый день, необходимо больше специалистов по обработке данных и инженеров по обработке данных, которые помогли бы понять эти данные. Сертификационный курс по проектированию данных Simplilearn в сотрудничестве с IBM и в партнерстве с Purdue University предлагает высочайший опыт обучения, который поможет вам овладеть важнейшими навыками проектирования данных.Эта программа, основанная на академических достижениях Университета Пердью в области инженерии данных и отраслевом и практическом опыте обучения IBM, поможет ускорить вашу карьеру в качестве специалиста по разработке данных.
Что такое обработка данных? Определение и этапы
Без обработки данных компании ограничивают свой доступ именно к данным, которые могут улучшить их конкурентное преимущество и предоставить критически важные бизнес-идеи. Вот почему всем компаниям важно понимать необходимость обработки всех своих данных и то, как это делать.
Вот почему всем компаниям важно понимать необходимость обработки всех своих данных и то, как это делать.
Что такое обработка данных?
Обработка данных происходит, когда данные собираются и преобразуются в полезную информацию. Обычно обработка данных выполняется специалистом по данным или группой специалистов по данным, поэтому важно, чтобы обработка данных выполнялась правильно, чтобы не повлиять на конечный продукт или вывод данных.
Обработка данных начинается с данных в их необработанном виде и преобразует их в более читаемый формат (графики, документы и т. Д.), Придавая им форму и контекст, необходимые для интерпретации компьютерами и использования сотрудниками всей организации.
Загрузите The Definitive Guide to Data Integration
прямо сейчас.
Прочитай сейчас
Шесть этапов обработки данных
1. Сбор данных
Сбор данных — это первый шаг в обработке данных. Данные берутся из доступных источников, включая озера данных и хранилища данных. Важно, чтобы доступные источники данных были надежными и хорошо построенными, чтобы собранные данные (а затем использованные в качестве информации) имели максимально возможное качество.
Данные берутся из доступных источников, включая озера данных и хранилища данных. Важно, чтобы доступные источники данных были надежными и хорошо построенными, чтобы собранные данные (а затем использованные в качестве информации) имели максимально возможное качество.
2. Подготовка данных
После того, как данные собраны, они перейдут на этап подготовки данных. Подготовка данных, часто называемая «предварительной обработкой», — это этап, на котором необработанные данные очищаются и организуются для следующего этапа обработки данных. Во время подготовки необработанные данные тщательно проверяются на наличие ошибок. Цель этого шага — удалить неверные данные (избыточные, неполные или неверные данные) и начать создавать высококачественные данные для лучшей бизнес-аналитики.
3. Ввод данных
Чистые данные затем вводятся в место назначения (возможно, в CRM, например, в Salesforce, или в хранилище данных, например, Redshift), и переводятся на понятный язык. Ввод данных — это первый этап, на котором необработанные данные начинают принимать форму полезной информации.
Ввод данных — это первый этап, на котором необработанные данные начинают принимать форму полезной информации.
4. Обработка
На этом этапе данные, введенные в компьютер на предыдущем этапе, фактически обрабатываются для интерпретации. Обработка выполняется с использованием алгоритмов машинного обучения, хотя сам процесс может незначительно отличаться в зависимости от источника обрабатываемых данных (озера данных, социальные сети, подключенные устройства и т. Д.)) и его предполагаемое использование (изучение рекламных шаблонов, медицинская диагностика с подключенных устройств, определение потребностей клиентов и т. д.).
5. Вывод / интерпретация данных
Этап вывода / интерпретации — это этап, на котором данные, наконец, становятся доступными для специалистов, не занимающихся данными. Он переведен, удобочитаем и часто в виде графиков, видео, изображений, обычного текста и т. Д.). Теперь сотрудники компании или учреждения могут начать самообслуживание данных для своих собственных проектов анализа данных.
6. Хранение данных
Заключительный этап обработки данных — хранение. После обработки всех данных они сохраняются для будущего использования. Хотя некоторая информация может быть использована сразу же, большая часть ее позже пригодится. Кроме того, правильно сохраненные данные необходимы для соблюдения законодательства о защите данных, такого как GDPR. Когда данные хранятся должным образом, члены организации могут быстро и легко получить к ним доступ при необходимости.
Будущее обработки данных
Будущее обработки данных находится в облаке.Облачные технологии основаны на удобстве современных методов электронной обработки данных и повышают ее скорость и эффективность. Более быстрые и качественные данные означают, что каждая организация может использовать больше данных и извлекать более ценные сведения.
Загрузите Почему ваше следующее хранилище данных должно быть в облаке
прямо сейчас.
Прочитай сейчас
По мере миграции больших данных в облако компании получают огромные преимущества. Облачные технологии больших данных позволяют компаниям объединить все свои платформы в одну легко адаптируемую систему. По мере изменений и обновлений программного обеспечения (как это часто бывает в мире больших данных) облачные технологии легко интегрируют новое со старым.
Облачные технологии больших данных позволяют компаниям объединить все свои платформы в одну легко адаптируемую систему. По мере изменений и обновлений программного обеспечения (как это часто бывает в мире больших данных) облачные технологии легко интегрируют новое со старым.
Преимущества облачной обработки данных никоим образом не ограничиваются крупными корпорациями. Фактически, небольшие компании могут получить большие выгоды сами. Облачные платформы могут быть недорогими и обеспечивать гибкость для роста и расширения возможностей по мере роста компании.Это дает компаниям возможность масштабироваться без высокой цены.
От обработки данных к аналитике
Большие данные меняют то, как все мы ведем бизнес. Сегодня сохранение гибкости и конкурентоспособности зависит от наличия четкой и эффективной стратегии обработки данных. Хотя шесть этапов обработки данных не изменятся, облако привело к огромному прогрессу в технологиях, которые на сегодняшний день предоставляют самые передовые, экономичные и быстрые методы обработки данных.
Станьте мастером обработки данных.
Загрузите бесплатную пробную версию Talend Cloud Integration Platform прямо сейчас.
Скачать бесплатную пробную версию Talend Cloud
5 типов обработки данных
Прежде чем вы сможете использовать какие-либо структурированные и неструктурированные данные, которые вы собираете, эти данные должны быть обработаны.
Самый простой пример обработки данных — визуализация данных. Например, большинство CRM могут выдавать отчеты об анализе данных в виде графиков. Однако, чтобы добраться до этой точки, данные подвергаются ряду операций преобразования.
Существует несколько различных типов обработки данных, которые, помимо прочего, различаются по доступности, атомарности и параллелизму.
Содержание
1. Почему имеет значение метод обработки данных?
2. Обработка транзакций
5. Распределенная обработка
Распределенная обработка
3. Обработка в реальном времени
4. Пакетная обработка
6.Многопроцессорность
7. Подготовка данных к обработке
Почему имеет значение метод обработки данных?
Используемый вами метод обработки данных определяет время ответа на запрос и надежность вывода. Таким образом, нужно тщательно выбирать метод. Например, в ситуации, когда доступность имеет решающее значение, такой как портал фондовой биржи, обработка транзакций должна быть предпочтительным методом.
Важно отметить разницу между обработкой данных и системой обработки данных.Обработка данных — это правила, по которым данные преобразуются в полезную информацию. Система обработки данных — это приложение, оптимизированное для определенного типа обработки данных. Например, система с разделением времени предназначена для оптимального выполнения обработки с разделением времени. Его также можно использовать для выполнения пакетной обработки. Однако он не очень хорошо масштабируется для работы.
Его также можно использовать для выполнения пакетной обработки. Однако он не очень хорошо масштабируется для работы.
В этом смысле, когда мы говорим о выборе правильного типа обработки данных для ваших нужд, мы имеем в виду выбор правильной системы.Ниже приведены наиболее распространенные типы обработки данных и их применения.
1. Обработка транзакцийОбработка транзакций развертывается в критически важных ситуациях. Это ситуации, которые в случае нарушения могут отрицательно повлиять на бизнес-операции. Например, обработка биржевых операций, как упоминалось ранее. При обработке транзакций доступность является наиболее важным фактором. На доступность могут влиять такие факторы, как:
- Оборудование: Система обработки транзакций должна иметь избыточное оборудование.Аппаратное резервирование допускает частичные отказы, поскольку резервные компоненты могут быть автоматизированы, чтобы взять на себя управление и поддерживать работу системы.

- Программное обеспечение: Программное обеспечение системы обработки транзакций должно быть спроектировано так, чтобы быстро восстанавливаться после сбоя. Обычно системы обработки транзакций используют для этого абстракцию транзакций. Проще говоря, в случае сбоя незавершенные транзакции прерываются. Это позволяет системе быстро перезагружаться.
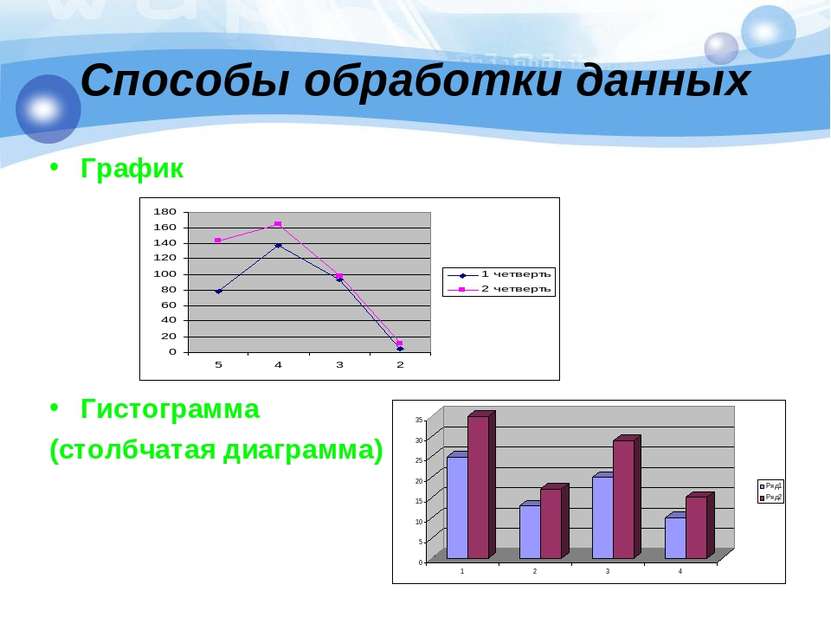
Очень часто наборы данных слишком велики, чтобы поместиться на одной машине. Распределенная обработка данных разбивает эти большие наборы данных и сохраняет их на нескольких машинах или серверах. Он основан на распределенной файловой системе Hadoop (HDFS). Система распределенной обработки данных отличается высокой отказоустойчивостью. Если один сервер в сети выходит из строя, задачи обработки данных могут быть перенесены на другие доступные серверы.
Распределенная обработка также может быть очень экономичной.Компаниям больше не нужно строить дорогие мэйнфреймы и вкладывать средства в их содержание и обслуживание.
Потоковая обработка и пакетная обработка являются распространенными примерами распределенной обработки, обе из которых обсуждаются ниже.
Вам нравится эта статья?
Получайте отличный контент еженедельно с новостной рассылкой Xplenty!
3. Обработка в реальном времениОбработка в реальном времени похожа на обработку транзакций в том, что она используется в ситуациях, когда ожидается вывод в реальном времени.Однако они отличаются тем, как они справляются с потерей данных. При обработке в реальном времени поступающие данные вычисляются максимально быстро. Если он обнаруживает ошибку во входящих данных, он игнорирует ошибку и переходит к следующему блоку входящих данных. Приложения GPS-слежения являются наиболее распространенным примером обработки данных в реальном времени.
Сравните это с обработкой транзакций. В случае ошибки, например сбоя системы, обработка транзакции прерывает текущую обработку и выполняет повторную инициализацию. Обработка в реальном времени предпочтительнее обработки транзакций в случаях, когда достаточно приблизительных ответов.
В мире аналитики данных потоковая обработка — это обычное применение обработки данных в реальном времени. Впервые популяризированная Apache Storm, потоковая обработка анализирует данные по мере их поступления. Считайте данные с датчиков Интернета вещей или отслеживание активности потребителей в режиме реального времени. Google BigQuery и Snowflake — это примеры платформ облачных данных, которые используют обработку в реальном времени.
4. Пакетная обработкаКак следует из названия, пакетная обработка — это когда блоки данных, хранящиеся в течение определенного периода времени, анализируются вместе или группами.Пакетная обработка требуется, когда для получения подробной информации необходимо проанализировать большой объем данных. Например, данные о продажах компании за определенный период времени обычно проходят пакетную обработку. Поскольку задействован большой объем данных, системе потребуется время для его обработки. Пакетная обработка данных позволяет сэкономить вычислительные ресурсы.
Пакетная обработка предпочтительнее обработки в реальном времени, когда точность важнее скорости. Кроме того, эффективность пакетной обработки также измеряется с точки зрения пропускной способности.Пропускная способность — это количество данных, обрабатываемых за единицу времени.
5. МногопроцессорностьМногопроцессорность — это метод обработки данных, при котором два или более чем два процессора работают с одним и тем же набором данных. Это может звучать в точности как распределенная обработка, но есть разница. При многопроцессорности разные процессоры находятся в одной системе. Таким образом, они находятся в одном географическом месте. Если произойдет сбой компонента, это может снизить скорость системы.
Распределенная обработка, с другой стороны, использует серверы, которые независимы друг от друга и могут находиться в разных географических точках. Поскольку сегодня почти все системы имеют возможность обрабатывать данные параллельно, почти каждая система обработки данных использует многопроцессорность.
Однако в контексте этой статьи многопроцессорность можно рассматривать как наличие локальной системы обработки данных. Как правило, компании, которые обрабатывают очень конфиденциальную информацию, могут выбрать локальную обработку данных, а не распределенную.Например, фармацевтические компании или предприятия, работающие в нефтегазодобывающей отрасли.
Самым очевидным недостатком такой обработки данных является стоимость. Строительство и обслуживание собственных серверов обходятся очень дорого.
Кейт подключил несколько источников данных к Amazon Redshift для преобразования, организации и анализа данных о клиентах. MongoDB Amazon Redshift
Дэйв Шуман
Технический директор и соучредитель Raise.мне
Они действительно предоставили интерфейс в этот мир преобразования данных, который работает. Это интуитивно понятно, с ним легко справиться […], и когда это становится для нас слишком запутанным, [служба поддержки клиентов Xplenty] иногда работает целый день, просто пытаясь помочь нам решить нашу проблему, и никогда не сдавайся, пока не решишь.
УЗНАЙ, МОЖЕМ ЛИ МЫ ИНТЕГРИРОВАТЬ ВАШИ ДАННЫЕКОМПАНИИ ПО ВСЕМУ МИРУ ДОВЕРЯЮТ
Вам нравится эта статья?
Получайте отличный контент еженедельно с новостной рассылкой Xplenty!
Подготовка данных к обработке
Прежде чем данные можно будет обработать и проанализировать, их необходимо подготовить, чтобы они могли быть прочитаны алгоритмами.Необработанные данные должны пройти ETL — извлечь, преобразовать, загрузить — чтобы попасть в ваше хранилище данных для обработки. Xplenty упрощает задачу подготовки ваших данных для анализа. С нашей облачной платформой вы можете создавать конвейеры данных ETL за считанные минуты. Простой графический интерфейс избавляет от необходимости писать сложный код. Прямо из коробки имеется поддержка интеграции для более чем 100 популярных хранилищ данных и приложений SaaS. И вы можете использовать API для быстрой настройки и гибкости.
С Xplenty вы можете тратить меньше времени на обработку ваших данных, поэтому у вас будет больше времени на их анализ.Узнайте больше, запланировав демонстрацию и испытав нашу платформу с низким кодом на себе.
ОБРАБОТКА ДАННЫХ НА КОМПЬЮТЕРЕ
ВведениеОбработка данных относится к преобразованию необработанных данных в осмысленный вывод.
Данные могут быть выполнены вручную с помощью ручки и бумаги, механически с помощью простых устройств, например, пишущей машинки или в электронном виде с использованием современных инструментов обработки данныхseg компьютеров
Сбор данных включает получение данных / фактов, необходимых для обработки из точка его происхождения к компьютеру
Ввод данных — собранные данные преобразуются в машиночитаемую форму устройством ввода и отправляются в машину.
Обработка — это преобразование входных данных в более значимую форму (информацию) в ЦП
Вывод — это производство необходимой информации, которая может быть введена в будущем.
Разница между сбором данных и сбором данных.
Сбор данных — это процесс получения данных в компьютерно-зависимой форме для точки происхождения (сам исходный документ готовится для ввода в машинно-ориентированной форме)
Сбор данных включает передачу исходных данных в «центр обработки», их расшифровку, преобразование с одного носителя на другой и, наконец, передачу их в компьютер.
Актуальность термина «мусор в мусоре на выходе» (GIGO) применительно к ошибкам при обработке данных.
Точность данных, вводимых в компьютер, напрямую определяет точность выданной информации.
Приведите и объясните две ошибки транскрипции и две вычислительные ошибки, допущенные во время обработки данных.
Ошибки неправильного чтения : — они возникают, когда пользователь неправильно читает исходный документ, таким образом вводя неправильные значения, например.грамм. пользователь может спутать 5 в числе 586 с S и вместо этого ввести S86.
Ошибки транспонирования : — они возникают из-за неправильного расположения символов (т. Е. Размещения символов в неправильном порядке, особенно при вводе данных на дискету), например пользователь может ввести 396 вместо 369 вычислительных ошибок
Ошибки переполнения : -Переполнение происходит, если результат вычисления слишком велик, чтобы поместиться в выделенном пространстве памяти, например, если выделенное пространство памяти может хранить 8-битный символ, тогда произойдет переполнение, если результат вычисления дает 9-битное число.
- Нижний край
- Усечение: 0,784969 784
- Ошибка округления: 30,6666 7
- Алгоритм или, логические ошибки
Целостность данных.
Под целостностью данных понимается надежность, своевременность, доступность, актуальность, точность и полнота данных / информации
Угрозы целостности данных
Целостность данных может быть нарушена через:
- Человеческая ошибка, злонамеренная или непреднамеренная.
- Ошибки передачи, включая непреднамеренные изменения или компрометацию данных во время передачи с одного устройства на другое.
- Ошибки, вирусы / вредоносное ПО, взлом и другие киберугрозы.
- Взломанное оборудование, например сбой устройства или диска.
Способы минимизации угроз целостности данных.
- Резервное копирование данных на внешний носитель
- Применение мер безопасности для контроля доступа к данным
- Использование программного обеспечения для обнаружения и исправления ошибок при передаче данных
- Разработка пользовательских интерфейсов, сводящих к минимуму вероятность ввода неверных данных.
Методы обработки данных
1. Ручная обработка данных
В ручной обработке данных данные обрабатываются вручную без использования какого-либо станка или инструмента для получения требуемых результатов. При ручной обработке данных все вычисления и логические операции выполняются с данными вручную. Точно так же данные переносятся вручную из одного места в другое.Этот метод обработки данных очень медленный, и на выходе могут возникать ошибки. Чаще всего обрабатывается вручную во многих малых предприятиях, а также в государственных учреждениях и учреждениях. В образовательном учреждении, например, ведомости оценок, квитанции об оплате и другие финансовые расчеты (или транзакции) выполняются вручную. Этого метода избегают, насколько это возможно, из-за очень высокой вероятности ошибки, трудоемкости и значительных затрат времени. Этот тип обработки данных представляет собой очень примитивную стадию, когда технологии не были доступны или были недоступны.С развитием технологий зависимость от ручных методов резко снизилась.
2. Механическая обработка данных
В методе обработки механических данных данные обрабатываются с помощью различных устройств, таких как пишущие машинки, механические принтеры или другие механические устройства. Этот метод обработки данных быстрее и точнее, чем ручная обработка данных. Это быстрее, чем в ручном режиме, но все же составляет раннюю стадию обработки данных.С изобретением и развитием более сложных машин с большей вычислительной мощностью этот тип обработки также начал исчезать. Экзаменационные доски и печатный станок часто используют механические устройства обработки данных.
3. Электронная обработка данных
Электронная обработка данных или EDP — это современный метод обработки данных. Данные обрабатываются через компьютер; Данные и набор инструкций передаются компьютеру в качестве входных данных, и компьютер автоматически обрабатывает данные в соответствии с заданным набором инструкций.Компьютер также известен как машина для электронной обработки данных.
Этот метод обработки данных очень быстрый и точный. Например, в компьютеризированной образовательной среде результаты учащихся подготавливаются с помощью компьютера; в банках счета клиентов ведутся (или обрабатываются) с помощью компьютеров и т. д.
а . Пакетная обработка
Пакетная обработка — это метод, при котором информация, которая должна быть организована, сортируется по группам для обеспечения эффективной и последовательной обработки.Онлайн-обработка — это метод, использующий подключение к Интернету и оборудование, непосредственно подключенное к компьютеру. Он используется в основном для записи информации и исследований. Обработка в реальном времени — это метод, позволяющий практически мгновенно реагировать на различные сигналы для сбора и обработки информации. Распределенная обработка обычно используется удаленными рабочими станциями, подключенными к одной большой центральной рабочей станции или серверу. Банкоматы — хорошие примеры этого метода обработки данных.
г. Онлайн-обработка
Это метод, использующий подключение к Интернету и оборудование, непосредственно подключенное к компьютеру. Это позволяет хранить данные в одном месте и использовать их в разных местах. Облачные вычисления можно рассматривать как пример, в котором используется этот тип обработки. Он используется в основном для записи информации и исследований.
г. Обработка в реальном времени
Этот метод позволяет практически немедленно реагировать на различные сигналы для сбора и обработки информации.Это связано с высокими затратами на обслуживание и начальными затратами, связанными с передовыми технологиями и вычислительной мощностью. В этом случае экономия времени максимальна, так как результат отображается в режиме реального времени. Например, в банковских транзакциях
Пример обработки в реальном времени
- Системы бронирования авиакомпаний
- Театр (кинотеатр) бронирование
- Бронирование гостиниц
- Банковские системы
- Системы дознания полиции
- Химические заводы
- Больницы для наблюдения за состоянием пациента
- Системы управления ракетами
- Предоставляет актуальную информацию
- Информация доступна для мгновенного принятия решений
- Предоставляет более качественные услуги пользователям / клиентам.
- Быстро и надежно
- Уменьшает тираж бумажных копий.
Недостатки
- Требуются сложные ОС и очень дороги
- Разрабатывать непросто
- Системы реального времени обычно используют 2 или более процессора для разделения рабочих нагрузок, что дорого.
- Требуется крупное коммуникационное оборудование.
г. Распределенная обработка
Этот метод обычно используется удаленными рабочими станциями, подключенными к одной большой центральной рабочей станции или серверу.Банкоматы — хорошие примеры этого метода обработки данных. Все конечные машины работают на фиксированном программном обеспечении, расположенном в определенном месте, и используют точно такую же информацию и наборы инструкций.
Различия между заданиями, связанными с ЦП, и заданиями, связанными с вводом-выводом.Задание, связанное с ЦП s требуется больше времени ЦП для обработки этих заданий. Большая часть работы, которую выполняют устройства ввода-вывода, приходится на ввод; и выход; следовательно, они требуют очень мало времени процессора.
Большинство компаний сейчас отказываются от использования географически распределенных персональных компьютеров. Этот метод обработки данных известен как Распределенная обработка данных (DDP)
Три вычислительных ресурса, которые могут быть распределены.
-CPU (процессоры) время
-Файлы
-Программное обеспечение
-Данные / информация / сообщения
-Производительность компьютера
-Память (компьютерная память)
— Устройства ввода / вывода, e.грамм. принтеры
-устройства связи / порт связи
Примеры отраслей и коммерческих организаций, широко использующих распределенные системы обработки.
- Банки
- Компьютеризированные магазины розничной торговли, например супермаркеты
- Учебные заведения с множеством отделений
- Бюро или коммуникационные интернет-кафе
- Системы бронирования авиакомпаний
Преимущества и три риска, которые могут быть связаны с системой распределенной обработки данных.
T Он значительно снижает нагрузку на главный компьютер
- Использование недорогих миникомпьютеров сводит к минимуму затраты на обработку данных
- Снижены задержки обработки данных
- Предоставляет более качественные услуги клиентам
- Риск выхода из строя системы меньше
- Разработка и внедрение системы менее сложны благодаря децентрализации
- Требуемый уровень знаний меньше.
Риски
- Дублирование данных очень распространено
- Проблемы при программировании микрокомпьютеров и миникомпьютеров
- Угрозы безопасности, то есть данные и информация, отправляемые по сети из одного места в
- другой может прослушиваться или прослушиваться неавторизованными сторонами
- Для участвующих пользователей требуется дополнительное обучение
- Дорого из-за дополнительной стоимости коммуникационного оборудования.
Концепция мультипрограммирования
Многопрограммная система позволяет пользователю одновременно запускать 2 или более программ, каждая из которых находится в основной памяти компьютера.
Преимущества мультипрограммирования
- Увеличивает производительность компьютера
- Сокращает время простоя ЦП
- Снижает частоту операций на периферических связях
Преимущества хранения данных в компьютерных файлах по сравнению с ручной системой хранения
- Хранимая информация занимает меньше места
- Легче обновлять и модифицировать
- Обеспечивает более быстрый доступ и поиск данных
- Уменьшает дублирование данных или хранимых записей
- Дешевле
- Повышает целостность данных (т.е. точность и полнота)
Разница между логическими и физическими компьютерными файлами.
Логический файл просматривается с точки зрения того, какие элементы данных он содержит и какие операции обработки могут выполняться с данными
Физический файл рассматривается с точки зрения того, как элементы данных, найденные в файле, расположены на носителе и как они могут быть обработаны.
Расположите следующие компоненты иерархии данных информационной системы в порядке возрастания сложности:
Поле, база данных, байт, запись, бит и файл
База данных файла записи поля битовых байтов
ВИДЫ КОМПЬЮТЕРНЫХ ФАЙЛОВ
i) Файл отчета — Он содержит набор относительно постоянных записей, извлеченных из данных в главном файле.
Они используются для подготовки отчетов, которые можно распечатать позже, например отчет об успеваемости ученика в семестре, выписка учеников, которые не уплатили плату за учебу, отчет о прогулах
ii) Резервный файл — Используется для резервного копирования данных или для хранения дубликатов данных / информации из фиксированного хранилища компьютера или основной файл в целях безопасности, например копия всех поступивших в школу учеников, отчет о заочных
iii) Справочный файл — используется в справочных целях.Он содержит записи, которые являются довольно постоянными или полупостоянными, например Удержания в размере страхового взноса, ставки заработной платы, налоговые вычеты, адреса сотрудников, прейскуранты и т. Д.
iv) Файл сортировки — используется для сортировки / ранжирования данных в соответствии с заданным порядком, например рейтинговое положение в классе студентов.v) Файл транзакции — Используется для хранения входных данных во время обработки транзакции. Позже он используется для обновления основных файлов и ежедневного, еженедельного или ежемесячного аудита транзакций.
МЕТОДЫ ОРГАНИЗАЦИИ ФАЙЛОВ
Что такое файловая организация?
- Это способ организации (расположения) записей в конкретном файле или любом дополнительном запоминающем устройстве в компьютере
- Относится к способу хранения данных в файле
- Организация файлов важна, потому что она определяет метод доступа, эффективность, гибкость и устройства хранения, которые будут использоваться.
Методы организации файлов
i) Последовательные и последовательные
В последовательной файловой организации записи хранятся в отсортированном порядке с использованием
ключевое поле, а в серийный ; записи хранятся в том порядке, в котором они поступают в файл, и никоим образом не сортируются.
ii) Случайное и индексно-последовательное
В случайной файловой организации записи хранятся в файле случайным образом и к ним осуществляется прямой доступ, в то время как в индексированной –последовательной записи хранятся последовательно, но доступ к ним осуществляется напрямую с помощью индекса.
iii) s Организация файлов erial
Записи в файле хранятся и доступны одна за другой на носителе данных
iv) Метод организации индексированного последовательного файла
Подобно последовательному методу, только индекс используется для того, чтобы компьютер мог найти отдельные записи на носителе.
РЕЖИМЫ ЭЛЕКТРОННОЙ ОБРАБОТКИ ДАННЫХ
Это способы, которыми компьютер под влиянием операционной системы предназначен для обработки данных, например,
a) Пакетная обработка — это выполнение серии заданий в программе на компьютере без ручного вмешательства (не интерактивный).Строго говоря, это режим обработки: выполнение серии программ, каждая из которых работает с набором или «пакетом» входных данных, а не с одним входом (который вместо этого будет пользовательским заданием ). Однако это различие в значительной степени утрачено, и последовательность шагов в пакетном процессе часто называют «заданием» или «пакетным заданием».
Пакетная обработка дает следующие преимущества: =
- Он может сместить время обработки задания на то, когда вычислительные ресурсы менее заняты.
- Это позволяет избежать простоя вычислительных ресурсов за счет поминутного ручного вмешательства и контроля.
- Поддерживая высокий общий коэффициент использования, он амортизирует компьютер, особенно дорогой.
- Позволяет системе использовать разные приоритеты для интерактивной и неинтерактивной работы.
- Вместо того, чтобы запускать одну программу несколько раз для обработки одной транзакции каждый раз, пакетные процессы будут запускать программу только один раз для многих транзакций, уменьшая накладные расходы системы.
Недостатки
— Пользователи не могут завершить процесс во время выполнения и должны ждать, пока выполнение не завершится.
б)
8 примеров обработки данных
Обработка данных — это серия операций, которые используют информацию для получения результата. Общие операции обработки данных включают проверку, сортировку, классификацию, вычисление, интерпретацию, организацию и преобразование данных. Ниже приведены иллюстративные примеры обработки данных.
Электроника
Цифровая камера преобразует необработанные данные с датчика в фотофайл, применяя серию алгоритмов на основе цветовой модели. Приложение для торговли акциями преобразует данные, представляющие миллионы сделок с акциями, в график, который может быстро понять трейдер. .Интеграция
В процессе интеграции данные перемещаются из одной системы в другую. Это включает в себя процесс передачи и преобразования формата данных. Биллинговая система для телекоммуникационных компаний рассчитывает ежемесячные платежи для клиентов на основе таких факторов, как план обслуживания клиента и использование ими данных за месяц.Сборы представлены в виде документа, который отправляется клиентам по почте. Весь процесс автоматизирован, и его контролирует команда биллинга.Транзакции
Банковский веб-сайт принимает запрос денежного перевода от пользователя, проверяя его и форматируя для обработки серверной системой.Мультимедиа
Веб-сайт принимает представленные пользователями мультимедийные материалы, такие как видео, и преобразует их в стандартный формат для отображения пользователям.Связь
Средство обмена сообщениями шифрует сообщение перед его отправкой, используя алгоритм шифрования и открытый ключ.Искусственный интеллект
Беспилотный автомобиль использует данные датчиков в реальном времени, чтобы определять, есть ли впереди пешеходы. Это достигается путем применения моделей, разработанных в процессе машинного обучения, когда искусственный интеллект проверяет миллионы часов данных датчиков, чтобы отработать обнаружение пешеходов.Вычислительная техника
Это полный список статей, которые мы написали о вычислениях.Если вам понравилась эта страница, добавьте в закладки Simplicable.
Список основных вычислительных терминов.
Распространенные типы текстовых файлов с разделителями.
Двоичный код полностью объяснен.
Обзор шестнадцатеричного числа в контексте вычислений.
Разница между прикладным ПО и сервисами.
Распространенные типы виртуальных машин.
Определение системы на микросхеме с примерами.
Определение встроенной системы с примерами.
Список методов, связанных с наукой о данных, управлением данными и другими практиками, связанными с данными.
Основные типы данных.
Определение темных данных с примерами.
Тайны информационного массажа.
Несколько полезных определений данных.
Определение аналитики с примерами.
Разница между данными и информацией.
Разница между жесткими данными и мягкими данными.
Определение читабельности.
Распространенные типы потери данных.
Самые популярные статьи о Simplicable за последний день.
Последние сообщения или обновления на Simplicable.
6 этапов цикла обработки данных | by PeerXP Team
Обработка данных — это просто преобразование необработанных данных в значимую информацию в процессе. Данные технически обрабатываются для получения результатов, которые приводят к решению проблемы или улучшению существующей ситуации.Подобно производственному процессу, он следует за циклом, в котором входные данные (необработанные данные) подаются в процесс (компьютерные системы, программное обеспечение и т. Д.) Для получения выходных данных (информации и идей).
Как правило, организации используют компьютерные системы для выполнения ряда операций с данными с целью представления, интерпретации или получения информации. Этот процесс включает в себя такие действия, как ввод данных, сводка, вычисления, хранение и т. Д. Полезные и информативные выходные данные представлены в различных соответствующих формах, таких как диаграммы, отчеты, графики, средства просмотра документов и т. Д.
1) Сбор — это первая стадия цикла, и она очень важна, поскольку качество собранных данных сильно повлияет на результат. Процесс сбора должен гарантировать, что собранные данные являются как определенными, так и точными, чтобы последующие решения, основанные на результатах, были действительными. На этом этапе предоставляется как базовая линия для измерения, так и цель, которую следует улучшить.
2) Подготовка — это преобразование данных в форму, подходящую для дальнейшего анализа и обработки.Необработанные данные не могут быть обработаны и должны проверяться на точность. Подготовка — это создание набора данных из одного или нескольких источников данных, который будет использоваться для дальнейшего исследования и обработки. Анализ данных, которые не были тщательно проверены на наличие проблем, может привести к весьма вводящим в заблуждение результатам, которые во многом зависят от качества подготовленных данных.
3) Входные данные — это задача, в которой проверенные данные кодируются или преобразуются в машиночитаемую форму, чтобы их можно было обрабатывать через приложение.Ввод данных осуществляется с помощью клавиатуры, сканера или ввода данных из существующего источника. Этот трудоемкий процесс требует скорости и точности. Большинство данных должны соответствовать формальному и строгому синтаксису, поскольку на этом этапе требуется большая вычислительная мощность для разбивки сложных данных. Из-за затрат многие предприятия прибегают к аутсорсингу на этом этапе.
4) Обработка — это когда данные подвергаются различным средствам и методам мощных технических манипуляций с использованием алгоритмов машинного обучения и искусственного интеллекта для генерации вывода или интерпретации данных.Процесс может состоять из нескольких потоков выполнения, которые одновременно выполняют инструкции, в зависимости от типа данных. Существуют такие приложения, как Anvesh, для обработки больших объемов разнородных данных за очень короткие промежутки времени.
5) Вывод и интерпретация — это этап, на котором обработанная информация теперь передается и отображается пользователю. Вывод предоставляется пользователям в различных форматах отчетов, таких как графические отчеты, аудио, видео или средства просмотра документов.Выходные данные необходимо интерпретировать так, чтобы они могли предоставить значимую информацию, которая будет определять будущие решения компании.
6) Хранилище — это последний этап цикла обработки данных, на котором данные и метаданные (информация о данных) хранятся для будущего использования. Важность этого цикла состоит в том, что он обеспечивает быстрый доступ к обработанной информации и ее извлечение, позволяя при необходимости передавать ее непосредственно на следующий этап. Anvesh использует специальные стандарты безопасности и защиты для хранения данных для будущего использования.
Цикл обработки данных представляет собой серию шагов, выполняемых для извлечения полезной информации из необработанных данных. Хотя каждый шаг должен выполняться по порядку, порядок является циклическим. Этап вывода и хранения может привести к повторению этапа сбора данных, что приведет к другому циклу обработки данных. Цикл
дает представление о том, как данные перемещаются и преобразуются от сбора к интерпретации и, в конечном итоге, используются в эффективных бизнес-решениях.
Традиционные методы обработки и обработки больших данных
Добро пожаловать! Хотели бы вы лучше понять разницу между традиционными и большими данными, где их искать и какие методы можно использовать для их обработки?
Отлично! Потому что это то, к чему стремится эта статья.Это первые шаги, которые вы должны сделать при работе с данными, так что это прекрасное место для начала, особенно если вы планируете карьеру в области науки о данных!
«Данные» — широкий термин, который может относиться к «необработанным фактам», «обработанным данным» или «информации». Чтобы убедиться, что мы находимся на одной странице, давайте разделим их, прежде чем переходить к деталям.
Мы собираем необработанных данных , затем обрабатываем , чтобы получить значимую информацию . Что ж, разделить их было легко! Теперь перейдем к деталям!
Что такое сырые данные?
Необработанные данные ( Также называется « необработанные фактов» или « первичные данные ») — это то, что вы накопили и сохранили на сервере, но не затронули.Это означает, что вы не можете сразу его проанализировать. Мы называем сбор необработанных данных «сбором данных», и это первое, что мы делаем.
Что такое большие данные? Большие данные против. Традиционные данные
Мы можем рассматривать данные как традиционные или как большие данные. Если вы новичок в этой идее, вы можете представить традиционные данные в виде таблиц, содержащих категориальные и числовые данные. Эти данные структурированы и хранятся в базах данных, которыми можно управлять с одного компьютера.Одним из способов сбора традиционных данных является опрос людей. Попросите их оценить, насколько им нравится продукт или опыт по шкале от 1 до 10.
Традиционные данные — это данные, к которым привыкло большинство людей. Например, «управление заказами» помогает отслеживать продажи, покупки, электронную торговлю и заказы на работу.
Большие данные , однако, совсем другое дело.
Как можно догадаться по названию, «большие данные» — это термин, зарезервированный для очень больших данных.
Вы также часто будете видеть, что он характеризуется буквой «V».Как в «3V больших данных ». Иногда у нас может быть 5, 7 или даже 11 V больших данных. Они могут включать — Vision , который у вас есть для больших данных, Value для больших данных, инструменты Visualization , которые вы используете, или Variability для согласованности больших данных. И так далее …
Однако следует помнить о следующих наиболее важных критериях:
ОбъемДля больших данных требуется колоссальный объем памяти, обычно распределяемой между множеством компьютеров.Его размер измеряется в терабайтах, петабайтах и даже эксабайтах.
РазновидностьЗдесь речь идет не только о числах и тексте; большие данные часто подразумевают работу с изображениями, аудиофайлами, мобильными данными и т. д.
СкоростьПри работе с большими данными цель состоит в том, чтобы как можно быстрее извлекать из них шаблоны. Где мы встречаемся с большими данными?
Ответ: во все большем количестве отраслей и компаний.Вот несколько ярких примеров.
Как одно из крупнейших онлайн-сообществ, «Facebook» отслеживает имена своих пользователей, личные данные, фотографии, видео, записанные сообщения и так далее. Это означает, что в их данных много разновидности . И с более чем 2 миллиардами пользователей по всему миру, объем данных, хранящихся на их серверах, огромен.
Давайте возьмем «данные финансовой торговли» в качестве дополнительного примера.
Что происходит, когда мы записываем курс акций каждые 5 секунд? Или каждую секунду? Мы получаем набор данных размером , объемный , требующий значительно больше памяти, дискового пространства и различных методов для извлечения из него значимой информации.
Как традиционные, так и большие данные дадут вам прочную основу для повышения удовлетворенности клиентов. Но с этими данными будут проблемы, поэтому, прежде всего, вы должны обработать их.
Как обрабатывать необработанные данные?
Давайте превратим эти необработанных данных в нечто красивое!
Первое, что нужно сделать после сбора достаточного количества необработанных данных , — это то, что мы называем «предварительной обработкой данных ». Это группа операций, которые преобразуют ваши необработанные данные в формат, более понятный и полезный для дальнейшей обработки.
Я полагаю, что этот шаг будет втиснут между необработанными данными и обработкой ! Может, стоит добавить сюда раздел…
Предварительная обработка данных: маркировка, очистка данных и отсутствующие значения
Итак, на что направлена «предварительная обработка данных»?
Он пытается исправить проблемы, которые могут возникнуть при сборе данных.
Например, в некоторых собранных вами данных о клиентах может быть зарегистрировано лицо 932 года или «Великобритания» в качестве его имени.Прежде чем приступить к любому анализу, вам необходимо пометить эти данные как недействительные или исправить их. Вот что такое предварительная обработка данных!
Давайте углубимся в методы, которые мы применяем при предварительной обработке как традиционных, так и больших необработанных данных ?
Маркировка классаЭто включает в себя присвоение точки данных правильному типу данных, другими словами, упорядочение данных по категориям.
Мы разделяем традиционные данные на 2 категории:
Одна категория — «числовая». Если вы храните количество товаров, продаваемых за день, вы отслеживаете числовые значения.Это числа, которыми вы можете манипулировать. Например, вы можете вычислить среднее количество товаров, проданных за день или месяц.
Другой ярлык — «категоричный» — здесь вы имеете дело с информацией, которой нельзя манипулировать с помощью математики. Например, профессия человека. Помните, что точки данных могут быть числами, но не числовыми. Их дата рождения — это число, которым вы не можете напрямую манипулировать, чтобы получить дополнительную информацию.
Подумайте об основных данных о клиентах.* (используемый набор данных взят из нашего курса SQL)
Мы будем использовать эту таблицу, содержащую текстовую информацию о покупателях, чтобы дать наглядный пример разницы между числовой переменной и категориальной переменной .
Обратите внимание на первый столбец, он показывает идентификаторы, присвоенные различным клиентам. Вы не можете манипулировать этими числами. «Средний» идентификатор — это не то, что может дать вам какую-либо полезную информацию. Это означает, что хотя они и являются числами, они не содержат числовых значений и представляют собой категориальных данных .
Теперь сфокусируемся на последней колонке. Это показывает, сколько раз клиент подавал жалобу. Вы можете манипулировать этими числами. Сложение их всех вместе, чтобы получить общее количество жалоб, является полезной информацией, поэтому это числовых данных. Другой пример, который мы можем рассмотреть, — это ежедневные исторические данные о ценах на акции. * это то, что мы используем в нашем курсе Python.
В наборе данных, который вы видите здесь, есть столбец, содержащий даты наблюдений, которые считаются категориальными данными .И столбец, содержащий цены акций, это числовых данных .
Когда вы работаете с большими данными, все становится немного сложнее. У вас гораздо больше разнообразия, помимо «числовых» и «категориальных» данных, например:
- Текстовые данные
- Данные цифрового изображения
- Цифровые видеоданные
- И цифровые аудиоданные
Также известен как « очистка данных» или « очистка данных» .
Цель очистки данных — иметь дело с несогласованными данными. Это может быть разных форм. Допустим, вы собрали набор данных, содержащий штаты США, и четверть названий написаны с ошибками. В этой ситуации вы должны выполнить определенные приемы, чтобы исправить эти ошибки. Вы должны очистить данные; разгадка кроется в названии!
Большие данные содержат больше типов данных и более широкий набор методов очистки данных. Существуют методы, которые проверяют, готово ли цифровое изображение к обработке.И существуют особые подходы, которые гарантируют, что качество audio вашего файла будет достаточным для продолжения.
Отсутствующие значения« Отсутствуют значения ». — это еще одна проблема, с которой вам придется иметь дело. Не каждый клиент предоставит вам все запрашиваемые данные. Часто может случиться так, что покупатель назовет вам свое имя и род занятий, но не свой возраст. Что делать в таком случае?
Следует ли игнорировать всю запись о клиенте? Или вы можете ввести средний возраст оставшихся клиентов?
Каким бы ни было лучшее решение, важно, чтобы вы очистили данные и обработали пропущенные значения, прежде чем вы сможете обрабатывать данные дальше.
Традиционные методы обработки данных: балансировка и перемешивание
Давайте перейдем к двум распространенным методам обработки традиционных данных.
БалансировкаПредставьте, что вы составили опрос для сбора данных о покупательских привычках мужчин и женщин. Допустим, вы хотите выяснить, кто потратит больше денег в выходные. Однако, когда вы закончите сбор данных, вы узнаете, что 80% респондентов были женщинами и только 20% мужчинами.
В этих условиях тенденции, которые вы обнаружите, будут больше ориентированы на женщин.Лучший способ противодействовать этой проблеме — применять методы балансировки. Например, взять равное количество респондентов из каждой группы, чтобы соотношение было 50/50.
Перестановка данныхПеремешивание наблюдений из вашего набора данных похоже на перемешивание колоды карт. Это гарантирует, что в вашем наборе данных нет нежелательных шаблонов, вызванных проблемным сбором данных. Перетасовка данных — это метод, который улучшает прогнозные характеристики и помогает избежать ложных результатов.
Но как избежать ложных результатов?
Ну, это подробный процесс, но в двух словах, перемешивание — это способ рандомизации данных. Если я возьму первые 100 наблюдений из набора данных, это не будет случайной выборкой. Сначала будут извлечены основные наблюдения. Если я перемешаю данные, я уверен, что когда я возьму 100 последовательных записей, они будут случайными (и, скорее всего, репрезентативными).
Методы обработки больших данных: интеллектуальный анализ и маскирование данных
Давайте рассмотрим некоторые конкретные методы работы с большими данными .
Анализ текстовых данныхПодумайте об огромном количестве текста, который хранится в цифровом формате. Что ж, сейчас ведется много научных проектов, направленных на извлечение конкретной текстовой информации из цифровых источников. Например, у вас может быть база данных, в которой хранится информация из научных статей о «маркетинговых расходах» — основной теме вашего исследования. Вы могли бы найти нужную информацию без особых проблем, если бы количество источников и объем текста, хранящегося в вашей базе данных, были достаточно низкими.Часто, хотя данных очень много. Он может содержать информацию из научных статей, статей в блогах, онлайн-платформ, частных файлов Excel и т. Д.
Это означает, что вам нужно будет извлечь информацию о «маркетинговых расходах» из многих источников. Другими словами, «больших данных». Непростая задача, которая привела к тому, что ученые и практики разработали методы «интеллектуального анализа текстовых данных».
Маскирование данныхЕсли вы хотите вести надежный бизнес или государственную деятельность, вы должны сохранять конфиденциальную информацию.Когда личные данные передаются в Интернете, вы должны применить к информации некоторые методы «маскировки данных», чтобы вы могли анализировать ее, не ставя под угрозу конфиденциальность участника.
Подобно перетасовке данных, маскирование данных может быть сложным. Он скрывает исходные данные с помощью случайных и ложных данных и позволяет проводить анализ и хранить всю конфиденциальную информацию в надежном месте. Примером применения маскировки данных к большим данным являются методы интеллектуального анализа данных с сохранением конфиденциальности.
Закончив обработку данных, вы получите нужную ценную и содержательную информацию.
Надеюсь, мы немного разобрались в различиях между традиционными и большими данными и в том, как мы их обрабатываем.
Для получения более подробной информации обо всем, что касается науки о данных, ознакомьтесь с нашей статьей «Определение науки о данных: что, где и как в науке о данных»!
Готовы сделать следующий шаг к карьере в области науки о данных?
Ознакомьтесь с нашим курсом по очистке и предварительной обработке данных с помощью pandas.Узнайте, как очищать данные из всех типов источников и предварительно обрабатывать их для реальной визуализации и анализа, применяя правильные статистические инструменты и передовые методы pandas.